# Chapter 20 Exceptions and State Management
# Defining “Exception”
When designing a type, you first imagine the various situations in which the type will be used. The type name is usually a noun, such as FileStream or StringBuilder. Then you define the properties, methods, events, and so on for the type. The way you define these members (property data types, method parameters, return values, and so forth) becomes the programmatic interface for your type. These members indicate actions that can be performed by the type itself or on an instance of the type. These action members are usually verbs such as Read, Write, Flush, Append, Insert, Remove, etc. When an action member cannot complete its task, the member should throw an exception.
💡重要提示:异常时指成员没有完成它的名称所宣称的行动。
Look at the following class definition.
internal sealed class Account { | |
public static void Transfer(Account from, Account to, Decimal amount) { | |
from -= amount; | |
to += amount; | |
} | |
} |
The Transfer method accepts two Account objects and a Decimal value that identifies an amount of money to transfer between accounts. Obviously, the goal of the Transfer method is to subtract money from one account and add money to another. The Transfer method could fail for many reasons: the from or to argument might be null; the from or to argument might not refer to an open account; the from account might have insufficient funds; the to account might have so much money in it that adding more would cause it to overflow; or the amount argument might be 0, negative, or have more than two digits after the decimal place.
When the Transfer method is called, its code must check for all of these possibilities, and if any of them are detected, it cannot transfer the money and should notify the caller that it failed by throwing an exception. In fact, notice that the Transfer method’s return type is void. This is because the Transfer method has no meaningful value to return; if it returns at all, it was successful. If it fails, it throws a meaningful exception.
Object-oriented programming allows developers to be very productive because you get to write code like this.
Boolean f = "Jeff".Substring(1, 1).ToUpper().EndsWith("E"); // true |
Here I’m composing my intent by chaining several operations together.1 This code was easy for me to write and is easy for others to read and maintain because the intent is obvious: take a string, grab a portion of it, uppercase that portion, and see if it ends with an “E.” This is great, but there is a big assumption being made here: no operation fails. But, of course, errors are always possible, so we need a way to handle those errors. In fact, there are many object-oriented constructs—constructors, getting/setting a property, adding/removing an event, calling an operator overload, calling a conversion operator—that have no way to return error codes, but these constructs must still be able to report an error. The mechanism provided by the Microsoft .NET Framework and all programming languages that support it is called exception handling.
💡重要提示 许多开发人员都错误地认为异常和某件事件的发生频率有关。例如,一个设计文件 Read 方法的开发人员可能会这样想:” 读取文件最终会抵达文件尾。由于抵达文件尾部是会发生,所以我设计这个 Read 方法返回一个特殊值来报告抵达了文件尾;我不让它抛出异常。“
问题在于,这是设计 Read 方法的开发人员的想法,而非调用 Read 方法的开发人员的想法。
设计 Read 方法的开发人员不可能知道这个方法的所有调用情形。所以,开发人员不可能知道 Read 的调用者是不是每次都会一路读取到文件尾。事实上,由于大多数文件包含的都是结构化数据,所以一路读取直至文件尾的情况是很少发生的。
💡小结:许多面向对象的构造 —— 构造器、获取和设置属性、添加和删除事件、调用操作符重载和调用转换操作符等 —— 都没办法返回错误代码,但它们仍然需要报告错误。Microsoft .NET Framework 和所有编程语言通过异常处理来解决这个问题。
# Exception-Handling Mechanics
In this section, I’ll introduce the mechanics and C# constructs needed in order to use exception handling, but it’s not my intention to explain them in great detail. The purpose of this chapter is to offer useful guidelines for when and how to use exception handling in your code. If you want more information about the mechanics and language constructs for using exception handling, see the .NET Framework documentation and the C# language specification. Also, the .NET Framework exceptionhandling mechanism is built using the Structured Exception Handling (SEH) mechanism offered by Windows. SEH has been discussed in many resources, including the book, Windows via C/C++, Fifth Edition, by myself and Christophe Nasarre (Microsoft Press, 2007), which contains three chapters devoted to SEH.
The following C# code shows a standard usage of the exception-handling mechanism. This code gives you an idea of what exception-handling blocks look like and what their purpose is. In the subsections after the code, I’ll formally describe the try, catch, and finally blocks and their purpose and provide some notes about their use.
private void SomeMethod() { | |
try { | |
// Put code requiring graceful recovery and/or cleanup operations here... | |
} | |
catch (InvalidOperationException) { | |
// Put code that recovers from an InvalidOperationException here... | |
} | |
catch (IOException) { | |
// Put code that recovers from an IOException here... | |
} | |
catch { | |
// Put code that recovers from any kind of exception other than those preceding this... | |
// When catching any exception, you usually re-throw the exception. | |
// I explain re-throwing later in this chapter. | |
throw; | |
} | |
finally { | |
// Put code that cleans up any operations started within the try block here... | |
// The code in here ALWAYS executes, regardless of whether an exception is thrown. | |
} | |
// Code below the finally block executes if no exception is thrown within the try block | |
// or if a catch block catches the exception and doesn't throw or re-throw an exception. | |
} |
This code demonstrates one possible way to use exception-handling blocks. Don’t let the code scare you—most methods have simply a try block matched with a single finally block or a try block matched with a single catch block. It’s unusual to have as many catch blocks as in this example. I put them there for illustration purposes.
# The try Block
A try block contains code that requires common cleanup operations, exception-recovery operations, or both. The cleanup code should be placed in a single finally block. A try block can also contain code that might potentially throw an exception. The exception-recovery code should be placed in one or more catch blocks. You create one catch block for each kind of exception that your application can safely recover from. A try block must be associated with at least one catch or finally block; it makes no sense to have a try block that stands by itself, and C# will prevent you from doing this.
💡重要提示:开发人员有时不知道应该在一个 try 块中放入多少代码。这据图取决于状态管理。如果在一个 try 块中执行多个可能抛出同一个异常类型的操作,但不同的操作有不同的异常恢复措施,就应该将每个操作都放到它自己的 try 块中,这样才能正确地恢复状态。
# The catch Block
A catch block contains code to execute in response to an exception. A try block can have zero or more catch blocks associated with it. If the code in a try block doesn’t cause an exception to be thrown, the CLR will never execute the code contained within any of its catch blocks. The thread will simply skip over all of the catch blocks and execute the code in the finally block (if one exists). After the code in the finally block executes, execution continues with the statement following the finally block.
The parenthetical expression appearing after the catch keyword is called the catch type. In C#, you must specify a catch type of System.Exception or a type derived from System.Exception. For example, the previous code contains catch blocks for handling an InvalidOperationException (or any exception derived from it) and an IOException (or any exception derived from it). The last catch block (which doesn’t specify a catch type) handles any exception except for the exception type specified by earlier catch blocks; this is equivalent to having a catch block that specifies a catch type of System.Exception except that you cannot access the exception information via code inside the catch block’s braces.
💡注意:用 Microsoft Visual Studio 调试 catch 块时,可在监视窗口中添加特殊变量名称 $Exception 来查看当前抛出的异常对象。
The CLR searches from top to bottom for a matching catch type, and therefore you should place the more specific exception types at the top. The most-derived exception types should appear first, followed by their base types (if any), down to System.Exception (or an exception block that doesn’t specify a catch type). In fact, the C# compiler generates an error if more specific catch blocks appear closer to the bottom because the catch block would be unreachable.
If an exception is thrown by code executing within the try block (or any method called from within the try block), the CLR starts searching for catch blocks whose catch type is the same type as or a base type of the thrown exception. If none of the catch types matches the exception, the CLR continues searching up the call stack looking for a catch type that matches the exception. If after reaching the top of the call stack, no catch block is found with a matching catch type, an unhandled exception occurs. I’ll talk more about unhandled exceptions later in this chapter.
After the CLR locates a catch block with a matching catch type, it executes the code in all inner finally blocks, starting from within the try block whose code threw the exception and stopping with the catch block that matched the exception. Note that any finally block associated with the catch block that matched the exception is not executed yet. The code in this finally block won’t execute until after the code in the handling catch block has executed.
After all the code in the inner finally blocks has executed, the code in the handling catch block executes. This code typically performs some operations to deal with the exception. At the end of the catch block, you have three choices:
Re-throw the same exception, notifying code higher up in the call stack of the exception.
Throw a different exception, giving richer exception information to code higher up in the call stack.
Let the thread fall out of the bottom of the catch block.
Later in this chapter, I’ll offer some guidelines for when you should use each of these techniques. If you choose either of the first two techniques, you’re throwing an exception, and the CLR behaves just as it did before: it walks up the call stack looking for a catch block whose type matches the type of the exception thrown.
If you pick the last technique, when the thread falls out of the bottom of the catch block, it immediately starts executing code contained in the finally block (if one exists). After all of the code in the finally block executes, the thread drops out of the finally block and starts executing the statements immediately following the finally block. If no finally block exists, the thread continues execution at the statement following the last catch block.
In C#, you can specify a variable name after a catch type. When an exception is caught, this variable refers to the System.Exception-derived object that was thrown. The catch block’s code can reference this variable to access information specific to the exception (such as the stack trace leading up to the exception). Although it’s possible to modify this object, you shouldn’t; consider the object to be read-only. I’ll explain the Exception type and what you can do with it later in this chapter.
💡注意:你的代码可向 AppDomain 的 FirstChanceException 事件登记,这样只要 AppDomain 中发生异常,就会收到通知。这个通知是在 CLR 开始搜索任何 catch 块之前发生的。欲知该事件的详情,请参见第 22 章 ”CLR 寄宿和 AppDomain”。
# The finally Block
A finally block contains code that’s guaranteed to execute.2 Typically, the code in a finally block performs the cleanup operations required by actions taken in the try block. For example, if you open a file in a try block, you’d put the code to close the file in a finally block.
private void ReadData(String pathname) { | |
FileStream fs = null; | |
try { | |
fs = new FileStream(pathname, FileMode.Open); | |
// Process the data in the file... | |
} | |
catch (IOException) { | |
// Put code that recovers from an IOException here... | |
} | |
finally { | |
// Make sure that the file gets closed. | |
if (fs != null) fs.Close(); | |
} | |
} |
If the code in the try block executes without throwing an exception, the file is guaranteed to be closed. If the code in the try block does throw an exception, the code in the finally block still executes, and the file is guaranteed to be closed, regardless of whether the exception is caught. It’s improper to put the statement to close the file after the finally block; the statement wouldn’t execute if an exception were thrown and not caught, which would result in the file being left open (until the next garbage collection).
A try block doesn’t require a finally block associated with it; sometimes the code in a try block just doesn’t require any cleanup code. However, if you do have a finally block, it must appear after any and all catch blocks. A try block can have no more than one finally block associated with it.
When a thread reaches the end of the code contained in a finally block, the thread simply starts executing the statements immediately following the finally block. Remember that the code in the finally block is cleanup code. This code should execute only what is necessary to clean up operations initiated in the try block. The code inside catch and finally blocks should be very short and should have a high likelihood of succeeding without itself throwing an exception. Usually the code in these blocks is just one or two lines of code.
It is always possible that exception-recovery code or cleanup code could fail and throw an exception. Although possible, it is unlikely and if it does happen it usually means that there is something very wrong somewhere. Most likely some state has gotten corrupted somewhere. If an exception is inadvertently thrown within a catch or finally block, the world will not come to an end—the CLR’s exception mechanism will execute as though the exception were thrown after the finally block. However, the CLR does not keep track of the first exception that was thrown in the corresponding try block (if any), and you will lose any and all information (such as the stack trace) available about the first exception. Probably (and hopefully), this new exception will not be handled by your code and the exception will turn into an unhandled exception. The CLR will then terminate your process, which is good because all the corrupted state will now be destroyed. This is much better than having your application continue to run with unpredictable results and possible security holes.
Personally, I think the C# team should have chosen different language keywords for the exceptionhandling mechanism. What programmers want to do is try to execute some piece of code. And then, if something fails, either recover from the failure and move on or compensate to undo some state change and continue to report the failure up to a caller. Programmers also want to have guaranteed cleanup no matter what happens.
The code on the left is what you have to write to make the C# compiler happy, but the code on the right is the way I prefer to think about it.

CLS 和非 CLS 异常
所有面向 CLR 的编程语言都必须支持抛出从 Exception 派生的对象,因为公共语言规范 (Common Language Specification, CLS) 对此进行了硬性规定。但是,CLR 实际允许抛出任何类型的实例,而且有些编程语言允许代码抛出非 CLS 相容的异常对象,比如一个 String , Int32 和 DateTime 等。C# 编译器只允许代码抛出从 Exception 派生的对象,而用其他一些语言写的代码不仅允许抛出 Exception 派生对象,还允许抛出非 Exception 派生对象。
许多程序员没有意识到 CLR 允许抛出任何对象来报告异常。大多数开发人员以为只有派生自 Exception 的对象才能抛出。在 CLR 的 2.0 版本之前,程序员写 catch 块来捕捉异常时,只能捕捉 CLS 相容的异常。如果一个 C# 方法调用了用另一种编程语言写的方法,而且那个方法抛出一个非 CLS 相容的异常,那么 C# 代码根本不能捕捉这个异常,从而造成一些安全隐患。
在 CLR 的 2.0 版本中,Microsoft 引入了新的 RuntimeWrappedException 类 (在命名空间 System.Runtime.CompilerServices 中定义)。该类派生自 Exception ,所以它是一个 CLS 相容的异常类型。 RuntimeWrappedException 类含有一个 Object 类型的一个 CLS 相容的异常类型。 RuntimeWrappedException 类含有一个 Object 类型的私有字段 (可通过 RuntimeWrappedException 类的只读属性 WrappedException 来访问)。在 CLR 2.0 中,非 CLS 相容的一个异常被抛出时,CLR 会自动构造 RuntimeWrappedException 类的实例,并初始化该实例的私有字段,使之引用实际抛出的对象。这样 CLR 就将非 CLS 相容的异常转变成了 CLS 相容的异常。所以,任何能捕捉 Exception 类型的代码,现在都能捕捉非 CLS 相容的异常,从而消除了潜在的安全隐患。
虽然 C# 编译器只允许开发人员抛出派生自 Exception 的对象,但在 C# 的 2.0 版本之前,C# 编译器确实允许开发人员使用以下形式的代码捕捉非 CLS 相容的异常:
private void SomeMethod() {
try {
// 需要得体地进行恢复和/或清理的代码放在这里
}
catch (Exception e) {
// C# 2.0 以前,这个块只能捕捉 CLS 相容的异常:
// 而现在,这个块能捕捉 CLS 相容和不相容的异常
throw; // 重新抛出捕捉到的任何东西
}
catch {
// 在所有版本的 C# 中,这个块可以捕捉 CLS 相容和不相容的异常
throw; // 重新抛出捕捉到的任何东西
}
}
现在,一些开发人员注意到 CLR 同时支持相容和不相容于 CLS 的异常,他们可能像上面展示的那样写两个 catch 块来捕捉这两种异常。为 CLR 2.0 或更高版本重新编译上述代码,第二个 catch 块永远执行不到,C# 编译器显示以下警告消息:
CS1058: 上一个 catch 子句已捕获所有异常。引发的所有非异常均被包装在 System.Runtime.CompilerServices.RuntimeWrappedException 中。
开发人员有两个办法迁移 .NET Framework 2.0 之前的代码。首先,两个 catch 块中的代码可以合并到一个 catch 块中,并删除其中的一个 catch 块中,并删除其中的一个 catch 块。这是推荐的办法。另外,还可以向 CLR 说明程序集中的代码想按照旧的规则行事。也就是说,告诉 CLR 你的 catch(Exception) 块不应捕捉新的 RuntimeWrappedException 类的一个实例。在这种情况下,CLR 不会将非 CLS 相容的对象包装到一个 RuntimeWrappedException 实例中,而且只有在你提供了一个没有指定任何类型的 catch 块时才调用你的代码。为了告诉 CLR 需要旧的行为,可向你的程序集应用 RuntimeCompatibilityAttribute 类的实例:
using System.Runtime.CompilerServices;
[assembly:RuntimeCompatibility(WrapNonExceptionThrows = false)]
注意,该特性影响的是整个程序集。在同一个程序集中,包装和不包装异常这两种处理方式不能同时存在。向包含旧代码的程序集 (假如 CLR 不支持在其中包装异常) 添加新代码 (希望 CLR 包装异常) 时要特别小心。
💡小结:.NET Framework 异常处理机制是用 Microsoft Windows 提供的结构化异常处理(Structured Exception Handling,SEH)机制构建的。一个 try 块至少要有一个关联的 catch 块或 finally 块,单独一个 try 块没有意义,C# 也不允许。一个 try 块可以关联 0 个或多个 catch 块。 catch 关键字后的圆括号中的表达式称为捕捉类型。C# 要求捕捉类型必须是 System.Exception 或者它的派生类型。CLR 自上而下搜索匹配的 catch 块,所以应该将具体的异常放在顶部。也就是说,首先出现的是派生程度最大的异常类型,接着是它们的基类型 (如果有的话),最后是 System.Exception (或者没有指定任何捕捉类型的 catch 块)。事实上,如果弄反了这个顺序,将较具体的 catch 块放在靠近底部的位置,C# 编译器会报错,因为这样的 catch 块是不可达的。在 try 块的代码 (或者从 try 块调用的任何方法) 中抛出异常,CLR 将搜索捕捉类型与抛出的异常相同 (或者是它的基类) 的 catch 块。如果没有任何捕捉类型与抛出异常匹配,CLR 会去调用栈 <sup>①</sup > 更高的一层搜索与异常匹配的捕捉类型。如果都到了调用栈的顶部,还是没有找到匹配的 catch 块,就会发生未处理的异常。一旦 CLR 找到匹配的 catch 块,就会执行内层所有 finally 块中的代码。所谓 “内存 finally 块” 是指从抛出异常的 try 块开始,到匹配异常的 catch 块之间的所有 finally 块。注意,匹配异常的那个 catch 块所关联的 finally 块尚未执行,该 finally 块中的代码一直要等到这个 catch 块中的代码执行完毕才会执行。所有内层 finally 块执行完毕之后,匹配异常的那个 catch 块中的代码才开始执行。C# 允许在捕捉类型后指定一个变量。捕捉到异常时,该变量将引用抛出的 System.Exception 派生对象。 catch 块的代码可通过引用该变量来访问异常的具体信息。虽然这个对象可以修改,但最好不要这么做,而应把它当成是只读的。 finally 块包含的是保证会执行的代码。一般在 finally 块中执行 try 块的行动所要求的资源清理操作。终止线程或卸载 AppDomain 会造成 CLR 抛出一个 ThreadAbortException ,使 finally 块能够执行。如果直接用 Win32 函数 TerminateThread 杀死线程,或者用 Win32 函数 TerminateProcess 或 System.Environment 的 FailFast 方法杀死进程, finally 块不会执行。当然,进程终止后, Windows 会清理该进程使用的所有资源。即使 catch 或 finally 块内部抛出了异常也不是世界末日 —— CLR 的异常机制仍会正常运转,好像异常是在 finally 块之后抛出的第一个异常,关于第一个异常的所有信息 (例如堆栈跟踪) 都将丢失
。这个新异常可能 (而且极有可能) 不会由你的代码处理,最终变成一个未处理的异常。在这种情况下,CLR 会终止你的进程。这是件好事情,因为损坏的所有状态现在都会被销毁。相较于让应用程序继续运行,造成不可预知的结果以及可能的安全漏洞,这样处理要好得多。
# The System.Exception Class
The CLR allows an instance of any type to be thrown for an exception—from an Int32 to a String and beyond. However, Microsoft decided against forcing all programming languages to throw and catch exceptions of any type, so they defined the System.Exception type and decreed that all CLScompliant programming languages must be able to throw and catch exceptions whose type is derived from this type. Exception types that are derived from System.Exception are said to be CLS-compliant. C# and many other language compilers allow your code to throw only CLS-compliant exceptions.
The System.Exception type is a very simple type that contains the properties described in Table 20-1. Usually, you will not write any code to query or access these properties in any way. Instead, when your application terminates due to an unhandled exception, you will look at these properties in the debugger or in a report that gets generated and written out to the Windows Application event log or crash dump.

I’d like to say a few words about System.Exception’s read-only StackTrace property. A catch block can read this property to obtain the stack trace indicating what methods were called that led up to the exception. This information can be extremely valuable when you’re trying to detect the cause of an exception so that you can correct your code. When you access this property, you’re actually calling into code in the CLR; the property doesn’t simply return a string. When you construct a new object of an Exception-derived type, the StackTrace property is initialized to null. If you were to read the property, you wouldn’t get back a stack trace; you would get back null.
When an exception is thrown, the CLR internally records where the throw instruction occurred. When a catch block accepts the exception, the CLR records where the exception was caught. If, inside a catch block, you now access the thrown exception object’s StackTrace property, the code that implements the property calls into the CLR, which builds a string identifying all of the methods between the place where the exception was thrown and the filter that caught the exception.
💡重要提示:抛出异常时,CLR 会重置异常起点;也就是说,CLR 只记录最新的异常对象的抛出位置。
The following code throws the same exception object that it caught and causes the CLR to reset its starting point for the exception.
private void SomeMethod() { | |
try { ... } | |
catch (Exception e) { | |
... | |
throw e; // CLR thinks this is where exception originated. | |
// FxCop reports this as an error | |
} | |
} |
In contrast, if you re-throw an exception object by using the throw keyword by itself, the CLR doesn’t reset the stack’s starting point. The following code re-throws the same exception object that it caught, causing the CLR to not reset its starting point for the exception.
private void SomeMethod() { | |
try { ... } | |
catch (Exception e) { | |
... | |
throw; // This has no effect on where the CLR thinks the exception | |
// originated. FxCop does NOT report this as an error | |
} | |
} |
In fact, the only difference between these two code fragments is what the CLR thinks is the original location where the exception was thrown. Unfortunately, when you throw or re-throw an exception, Windows does reset the stack’s starting point. So if the exception becomes unhandled, the stack location that gets reported to Windows Error Reporting is the location of the last throw or re-throw, even though the CLR knows the stack location where the original exception was thrown. This is unfortunate because it makes debugging applications that have failed in the field much more difficult. Some developers have found this so intolerable that they have chosen a different way to implement their code to ensure that the stack trace truly reflects the location where an exception was originally thrown.
private void SomeMethod() { | |
Boolean trySucceeds = false; | |
try { | |
... | |
trySucceeds = true; | |
} | |
finally { | |
if (!trySucceeds) { /* catch code goes in here */ } | |
} | |
} |
The string returned from the StackTrace property doesn’t include any of the methods in the call stack that are above the point where the catch block accepted the exception object. If you want the complete stack trace from the start of the thread up to the exception handler, you can use the System.Diagnostics.StackTrace type. This type defines some properties and methods that allow a developer to programmatically manipulate a stack trace and the frames that make up the stack trace.
You can construct a StackTrace object by using several different constructors. Some constructors build the frames from the start of the thread to the point where the StackTrace object is constructed. Other constructors initialize the frames of the StackTrace object by using an Exceptionderived object passed as an argument.
If the CLR can find debug symbols (located in the .pdb files) for your assemblies, the string returned by System.Exception’s StackTrace property or System.Diagnostics.StackTrace’s ToString method will include source code file paths and line numbers. This information is incredibly useful for debugging.
Whenever you obtain a stack trace, you might find that some methods in the actual call stack don’t appear in the stack trace string. There are two reasons for this. First, the stack is really a record of where the thread should return to, not where the thread has come from. Second, the just-in-time (JIT) compiler can inline methods to avoid the overhead of calling and returning from a separate method. Many compilers (including the C# compiler) offer a /debug command-line switch. When this switch is used, these compilers embed information into the resulting assembly to tell the JIT compiler not to inline any of the assembly’s methods, making stack traces more complete and meaningful to the developer debugging the code.
💡注意:JIT 编译器会检查应用于程序集的 System.Diagnostics.Debuggabletrribute 定制特性。C# 编译器会自动应用该特性。如果该特性指定了 DisableOptimizations 标志,JIT 编译器就不会对程序集的方法进行内联。使用 C# 编译器的 /debug 开关就会设置这个标志。另外,向方法应用定制特性 System.Runtime.CompilerServices.MethodImplAttribute 将禁止 JIT 编译器在调试和发布生成 (debug and release build) 时对该方法进行内联处理,以下方法定义示范了如何禁止方法内联:
using System;
using System.Runtime.CompilerServices;
internal sealed class SomeType {
[MethodImpl(MethodImplOptions.NoInlining)]
public void SomeMethod() {
...
}
}
💡小结:CLR 允许异常抛出任何类型的实例 —— 从 Int32 到 String 都可以。而 C# 定义了 System.Exception 类型,并规定所有 CLS 相容的编程语言都必须能抛出和捕捉派生自该类型的异常。派生自 System.Exception 的异常类型被认为是 CLS 相容的。C# 和其他许多语言的编译器都只允许抛出 CLS 相容的异常。 System.Exception 定义了一些属性。但一般不要写任何代码以任何方式查询或访问这些属性。相反,当应用程序因为未处理的异常而终止时,可以在调试器中查看这些属性,或者在 Windows 应用程序事件日志或崩溃转储 (crash dump) 中查看。构造 Exception 派生类型的新对象时, StackTrace 属性被初始化为 null 。如果此时读取该属性,得到的不是堆栈跟踪,而是一个 null 。一个异常抛出时,CLR 在内部记录 throw 指令的位置 (抛出位置)。一个 catch 块捕捉到该异常时,CLR 记录捕捉位置。在 catch 块内访问被抛出的异常对象的 StackTrace 属性,负责实现该属性的代码会调用 CLR 内部的代码,后者创建一个字符串来指出从异常抛出位置到异常捕捉位置的所有方法。但如果仅仅使用 throw 关键字本身 (删除后面的 e ) 来重新抛出异常对象,CLR 就不会重置堆栈的起点。以下代码重新抛出它捕捉到的异常,但不会导致 CLR 重置起点。遗憾的是,不管抛出还是重新抛出异常,Windows 都会重置栈的起点。因此,如果一个异常成为未处理的异常,那么向 Windows Error Reporting 报告的栈位置就是最后一次抛出或重新抛出的位置 (即使 CLR 知道异常的原始抛出位置)。 StackTrace 属性返回的字符串不包含调用栈中比较受异常对象的那个 catch 块高的任何方法(栈顶移动即 “升高”,向栈底移动即 “降低”)。要获得从线程起始处到异常处理程序(catch 块)之间的完整堆栈追踪,需要使用 System.Diagnostics.StackTrace 类型。该类型定义了一些属性和方法,允许开发人员程序化地处理堆栈跟踪以及构成堆栈跟踪的栈桢(栈桢 (stack frame) 代表当前线程的调用栈中的一个方法调用。执行线程的过程中进行的每个方法调用都会在调用栈中创建并压入一个 StackFrame )。如果 CLR 能找到你的程序集的调试符号 (存储在.pdb 文件中),那么在 System.Exception 的 StackTrace 属性或者 System.Diagnostics.StackTrace 的 ToString 方法返回的字符串中,将包括源代码文件路径和代码行号,这些信息对于调试是很有用的。获得堆栈跟踪后,可能发现实际调用栈中的一些方法没有出现在堆栈跟踪字符串中。这可能有两方面的原因。首先,调用栈记录的是线程的返回位置 (而非来源位置)。其次, JIT 编译器可能进行了优化,将一些方法内联 (inline),以避免调用单独的方法并从中返回的开销。许多编译器 (包括 C# 编译器) 都支持 /debug 命令行开关。使用这个开关,编译器会在生成的程序集中嵌入信息,告诉 JIT 编译器不要内联程序集的任何方法,确保调试人员获得更完整、更有意义的堆栈跟踪。
# FCL-Defined Exception Classes
The Framework Class Library (FCL) defines many exception types (all ultimately derived from System. Exception). The following hierarchy shows the exception types defined in the MSCorLib.dll assembly; other assemblies define even more exception types. (The application used to obtain this hierarchy is shown in Chapter 23, “Assembly Loading and Reflection.”)
System.Exception | |
System.AggregateException | |
System.ApplicationException | |
System.Reflection.InvalidFilterCriteriaException | |
System.Reflection.TargetException | |
System.Reflection.TargetInvocationException | |
System.Reflection.TargetParameterCountException | |
System.Threading.WaitHandleCannotBeOpenedException | |
System.Diagnostics.Tracing.EventSourceException | |
System.InvalidTimeZoneException | |
System.IO.IsolatedStorage.IsolatedStorageException | |
System.Threading.LockRecursionException | |
System.Runtime.CompilerServices.RuntimeWrappedException | |
System.SystemException | |
System.Threading.AbandonedMutexException | |
System.AccessViolationException | |
System.Reflection.AmbiguousMatchException | |
System.AppDomainUnloadedException | |
System.ArgumentException | |
System.ArgumentNullException | |
System.ArgumentOutOfRangeException | |
System.Globalization.CultureNotFoundException | |
System.Text.DecoderFallbackException | |
System.DuplicateWaitObjectException | |
System.Text.EncoderFallbackException | |
System.ArithmeticException | |
System.DivideByZeroException | |
System.NotFiniteNumberException | |
System.OverflowException | |
System.ArrayTypeMismatchException | |
System.BadImageFormatException | |
System.CannotUnloadAppDomainException | |
System.ContextMarshalException | |
System.Security.Cryptography.CryptographicException | |
System.Security.Cryptography.CryptographicUnexpectedOperationException | |
System.DataMisalignedException | |
System.ExecutionEngineException | |
System.Runtime.InteropServices.ExternalException | |
System.Runtime.InteropServices.COMException | |
System.Runtime.InteropServices.SEHException | |
System.FormatException | |
System.Reflection.CustomAttributeFormatException | |
System.Security.HostProtectionException | |
System.Security.Principal.IdentityNotMappedException | |
System.IndexOutOfRangeException | |
System.InsufficientExecutionStackException | |
System.InvalidCastException | |
System.Runtime.InteropServices.InvalidComObjectException | |
System.Runtime.InteropServices.InvalidOleVariantTypeException | |
System.InvalidOperationException | |
System.ObjectDisposedException | |
System.InvalidProgramException | |
System.IO.IOException | |
System.IO.DirectoryNotFoundException | |
System.IO.DriveNotFoundException | |
System.IO.EndOfStreamException | |
System.IO.FileLoadException | |
System.IO.FileNotFoundException | |
System.IO.PathTooLongException | |
System.Collections.Generic.KeyNotFoundException | |
System.Runtime.InteropServices.MarshalDirectiveException | |
System.MemberAccessException | |
System.FieldAccessException | |
System.MethodAccessException | |
System.MissingMemberException | |
System.MissingFieldException | |
System.MissingMethodException | |
System.Resources.MissingManifestResourceException | |
System.Resources.MissingSatelliteAssemblyException | |
System.MulticastNotSupportedException | |
System.NotImplementedException | |
System.NotSupportedException | |
System.PlatformNotSupportedException | |
System.NullReferenceException | |
System.OperationCanceledException | |
System.Threading.Tasks.TaskCanceledException | |
System.OutOfMemoryException | |
System.InsufficientMemoryException | |
System.Security.Policy.PolicyException | |
System.RankException | |
System.Reflection.ReflectionTypeLoadException | |
System.Runtime.Remoting.RemotingException | |
System.Runtime.Remoting.RemotingTimeoutException | |
System.Runtime.InteropServices.SafeArrayRankMismatchException | |
System.Runtime.InteropServices.SafeArrayTypeMismatchException | |
System.Security.SecurityException | |
System.Threading.SemaphoreFullException | |
System.Runtime.Serialization.SerializationException | |
System.Runtime.Remoting.ServerException | |
System.StackOverflowException | |
System.Threading.SynchronizationLockException | |
System.Threading.ThreadAbortException | |
System.Threading.ThreadInterruptedException | |
System.Threading.ThreadStartException | |
System.Threading.ThreadStateException | |
System.TimeoutException | |
System.TypeInitializationException | |
System.TypeLoadException | |
System.DllNotFoundException | |
System.EntryPointNotFoundException | |
System.TypeAccessException | |
System.TypeUnloadedException | |
System.UnauthorizedAccessException | |
System.Security.AccessControl.PrivilegeNotHeldException | |
System.Security.VerificationException | |
System.Security.XmlSyntaxException | |
System.Threading.Tasks.TaskSchedulerException | |
System.TimeZoneNotFoundException |
💡小结:Microsoft 本来是打算将 System.Exception 类型作为所有异常的基类型,而另外两个类型 System.SystemException 和 System.ApplicationException 是唯一直接从 Exception 派生的类型。另外,CLR 抛出的所有异常都从 SystemException 派生,应用程序抛出的所有异常都从 ApplicationException 派生。这样就可以写一个 catch 块来捕捉 CLR 抛出的所有异常或者应用程序抛出的所有异常。但实际上规则没有得到严格遵守,因此结构一团糟。
# Throwing an Exception
When implementing your own methods, you should throw an exception when the method cannot complete its task as indicated by its name. When you want to throw an exception, there are two issues that you really need to think about and consider.
The first issue is about which Exception-derived type you are going to throw. You really want to select a type that is meaningful here. Consider the code that is higher up the call stack and how that code might want to determine that a method failed in order to execute some graceful recovery code. You can use a type that is already defined in the FCL, but there may not be one in the FCL that matches your exact semantics. So you’ll probably need to define your own type, ultimately derived from System.Exception.
If you want to define an exception type hierarchy, it is highly recommended that the hierarchy be shallow and wide in order to create as few base classes as possible. The reason is that base classes act as a way of treating lots of errors as one error, and this is usually dangerous. Along these lines, you should never throw a
System.Exceptionobject, and you should use extreme caution if you throw any other base class exception type.
💡重要提示:还要考虑版本问题。如果定义从现有异常类型派生的一个新异常类型,捕捉现有基类型的所有代码也能捕捉新类型。这有时可能正好是你期望的,但有时也可能不是,具体取决于捕捉基类的代码以什么样的方式响应异常类型及其派生类型。从未预料到会有新异常的代码现在可能出现非预期的行为,并可能留下安全隐患。而定义新异常类型的人一般不知道基异常的所有捕捉位置以及具体处理方式。所以这里事实不可能做出面面俱到的决定。
The second issue is about deciding what string message you are going to pass to the exception type’s constructor. When you throw an exception, you should include a string message with detailed information indicating why the method couldn’t complete its task. If the exception is caught and handled, this string message is not seen. However, if the exception becomes an unhandled exception, this message is usually logged. An unhandled exception indicates a true bug in the application, and a developer must get involved to fix the bug. An end user will not have the source code or the ability to fix the code and recompile it. In fact, this string message should not be shown to an end user. So these string messages can be very technically detailed and as geeky as is necessary to help developers fix their code.
Furthermore, because all developers have to speak English (at least to some degree, because programming languages and the FCL classes and methods are in English), there is usually no need to localize exception string messages. However, you may want to localize the strings if you are building a class library that will be used by developers who speak different languages. Microsoft localizes the exception messages thrown by the FCL, because developers all over the world will be using this class library.
💡小结:强烈建议定义浅而宽的异常类型层次结构 <sup>①</sup>,以创建尽量少的基类。原因是基类的主要作用就是将大量错误当作一个错误,而这通常是危险的。基于同样的考虑,永远都不要抛出一个 System.Exception 对象 <sup>②</sup>,抛出其他任何基类异常类型时也要特别谨慎。向异常类型传递的字符串信息应详细说明方法为什么无法完成任务。如果异常被捕捉到并进行了处理,用户就看不到该字符串的信息。但是,如果成为未处理的异常,消息通常会被写入日志。这个字符串消息根本不应该向最终用户显式,所以,字符串消息可以包含非常详细的技术细节,以帮助开发人员修正代码。
# Defining Your Own Exception Class
Unfortunately, designing your own exception is tedious and error prone. The main reason for this is because all Exception-derived types should be serializable so that they can cross an AppDomain boundary or be written to a log or database. There are many issues related to serialization and they are discussed in Chapter 24, “Runtime Serialization.” So, in an effort to simplify things, I made my own generic Exception class, which is defined as follows.
[Serializable] | |
public sealed class Exception<TExceptionArgs> : Exception, ISerializable | |
where TExceptionArgs : ExceptionArgs { | |
private const String c_args = "Args"; // For (de)serialization | |
private readonly TExceptionArgs m_args; | |
public TExceptionArgs Args { get { return m_args; } } | |
public Exception(String message = null, Exception innerException = null) | |
: this(null, message, innerException) { } | |
public Exception(TExceptionArgs args, String message = null, | |
Exception innerException = null): base(message, innerException) { m_args = args; } | |
// This constructor is for deserialization; since the class is sealed, the constructor is | |
// private. If this class were not sealed, this constructor should be protected | |
[SecurityPermission(SecurityAction.LinkDemand, | |
Flags=SecurityPermissionFlag.SerializationFormatter)] | |
private Exception(SerializationInfo info, StreamingContext context) | |
: base(info, context) { | |
m_args = (TExceptionArgs)info.GetValue(c_args, typeof(TExceptionArgs)); | |
} | |
// This method is for serialization; it’s public because of the ISerializable interface | |
[SecurityPermission(SecurityAction.LinkDemand, | |
Flags=SecurityPermissionFlag.SerializationFormatter)] | |
public override void GetObjectData(SerializationInfo info, StreamingContext context) { | |
info.AddValue(c_args, m_args); | |
base.GetObjectData(info, context); | |
} | |
public override String Message { | |
get { | |
String baseMsg = base.Message; | |
return (m_args == null) ? baseMsg : baseMsg + " (" + m_args.Message + ")"; | |
} | |
} | |
public override Boolean Equals(Object obj) { | |
Exception<TExceptionArgs> other = obj as Exception<TExceptionArgs>; | |
if (other == null) return false; | |
return Object.Equals(m_args, other.m_args) && base.Equals(obj); | |
} | |
public override int GetHashCode() { return base.GetHashCode(); } | |
} |
And the ExceptionArgs base class that TExceptionArgs is constrained to is very simple and looks like this.
[Serializable] | |
public abstract class ExceptionArgs { | |
public virtual String Message { get { return String.Empty; } } | |
} |
Now, with these two classes defined, I can trivially define more exception classes when I need to. To define an exception type indicating the disk is full, I simply do the following.
[Serializable] | |
public sealed class DiskFullExceptionArgs : ExceptionArgs { | |
private readonly String m_diskpath; // private field set at construction time | |
public DiskFullExceptionArgs(String diskpath) { m_diskpath = diskpath; } | |
// Public read-only property that returns the field | |
public String DiskPath { get { return m_diskpath; } } | |
// Override the Message property to include our field (if set) | |
public override String Message { | |
get { | |
return (m_diskpath == null) ? base.Message : "DiskPath=" + m_diskpath; | |
} | |
} | |
} |
And, if I have no additional data that I want to put inside the class, it gets as simple as the following.
[Serializable] | |
public sealed class DiskFullExceptionArgs : ExceptionArgs { } |
And now I can write code like this, which throws and catches one of these.
public static void TestException() { | |
try { | |
throw new Exception<DiskFullExceptionArgs>( | |
new DiskFullExceptionArgs(@"C:\"), "The disk is full"); | |
} | |
catch (Exception<DiskFullExceptionArgs> e) { | |
Console.WriteLine(e.Message); | |
} | |
} |
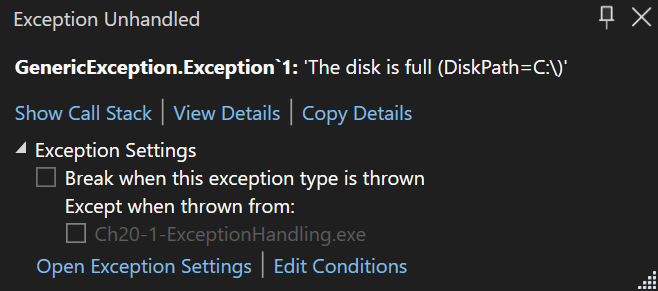
💡注意:我的 Exception<TExceptionArgs> 类有两个问题需要注意。第一个问题是,用它定义的任何异常类型都总是派生自 System.Exception 。这在大多数时候都不是问题,而且浅而宽的异常类型层次结构还是一件好事。第二个问题是,Visual Studio 的未处理异常对话框不会显示 Exception<T> 类型的泛型类型参数,如下图所示。
💡小结:设计自己的异常不仅繁琐,还容易出错。主要原因是从 Exception 派生的所有类型都应该是可序列化的(serializable),使它们能穿越 AppDomain 边界或者写入日志 / 数据库。
# Trading Reliability for Productivity
I started writing software in 1975. I did a fair amount of BASIC programming, and as I got more interested in hardware, I switched to assembly language. Over time, I switched to the C programming language because it allowed me access to hardware with a much higher level of abstraction, making my programming easier. My background is in writing operating systems’ code and platform/library code, so I always work hard to make my code as small and as fast as possible, because applications can only be as good as the operating system and libraries they consume.
In addition to creating small and fast code, I always focused on error recovery. When allocating memory (by using C++’s new operator or by calling malloc, HeapAlloc, VirtualAlloc, etc.), I would always check the return value to ensure that the memory I requested was actually given to me. And, if the memory request failed, I always had an alternate code path ensuring that the rest of the program’s state was unaffected and would let any of my callers know that I failed so that the calling code can take corrective measures too.
For some reason that I can’t quite explain, this attention to detail is not done when writing code for the .NET Framework. Getting an out-of-memory situation is always possible and yet I almost never see any code containing a catch block to recover from an OutOfMemoryException. In fact, I’ve even had some developers tell me that the CLR doesn’t let a program catch an OutOfMemoryException. For the record, this is absolutely not true; you can catch this exception. In fact, there are many errors that are possible when executing managed code and I hardly ever see developers write code that attempts to recover from these potential failures. In this section, I’d like to point out some of the potential failures and why it has become culturally acceptable to ignore them. I’d also like to point out some of the significant problems that can occur when ignoring these failures and suggest some ways to help mitigate these problems.
Object-oriented programming allows developers to be very productive. A big part of this is composability which makes it easy to write, read and maintain code. Take this line of code, for example.
Boolean f = "Jeff".Substring(1, 1).ToUpper().EndsWith("E"); |
There is a big assumption being made with the preceding code: no errors occur. But, of course, errors are always possible, and so we need a way to handle those errors. This is what the exception handling constructs and mechanisms are all about and why we need them as opposed to having methods that return true/false or an HRESULT to indicate success/failure the way that Win32 and COM functions do.
In addition to code composability, we are productive due to all kinds of great features provided by our compilers. For example, the compiler implicitly:
Inserts optional parameters when calling a method.
Boxes value type instances.
Constructs/initializes parameter arrays.
Binds to members of dynamic variables and expressions.
Binds to extension methods.
Binds/invokes overloaded operators.
Constructs delegate objects.
Infers types when calling generic methods, declaring a local variable, and using a lambda expression.
Defines/constructs closure classes for lambda expressions and iterators.
Defines/constructs/initializes anonymous types and instances of them.
Rewrites code to support Language Integrated Queries (LINQs; query expressions and expression trees).
And, the CLR itself does all kinds of great things for developers to make our lives even easier. For example, the CLR implicitly:
Invokes virtual methods and interface methods.
Loads assemblies and JIT-compiles methods that can potentially throw FileLoadException, BadImageFormatException, InvalidProgramException, FieldAccessException, MethodAccessException, MissingFieldException, MissingMethodException, and VerificationException.
Transitions across AppDomain boundaries when accessing an object of a MarshalByRefObject-derived type which can potentially throw AppDomainUnloadedException.
Serializes and deserializes objects when crossing an AppDomain boundary.
Causes thread(s) to throw a ThreadAbortException when Thread.Abort or AppDomain.Unload is called.
Invokes Finalize methods after a garbage collection before objects have their memory reclaimed.
Creates type objects in the loader heap when using generic types.
Invokes a type’s static constructor potential throwing of TypeInitializationException.
Throws various exceptions, including OutOfMemoryException, DivideByZeroException, NullReferenceException, RuntimeWrappedException, TargetInvocationException, OverflowException, NotFiniteNumberException, ArrayTypeMismatchException, DataMisalignedException, IndexOutOfRangeException, InvalidCastException, RankException, SecurityException, and more.
And, of course, the .NET Framework ships with a massive class library that contains tens of thousands of types, each type encapsulating common, reusable functionality. There are types for building web form applications, web services, rich GUI applications, working with security, manipulation of images, speech recognition, and the list goes on and on. Any of this code could throw an exception, indicating failure. And future versions could introduce new exception types derived from existing exception types and now your catch blocks catch exception types that never existed before.
All of this stuff—object-oriented programming, compiler features, CLR features, and the enormous class library—is what makes the .NET Framework such a compelling software development platform.4 My point is that all of this stuff introduces points of failure into your code, which you have little control over. As long as everything is working great, all is well: we write code easily, the code is easy to read and maintain. But, when something goes wrong, it is nearly impossible to fully understand what went wrong and why.
Here is an example that should really help get my point across.
private static Object OneStatement(Stream stream, Char charToFind) { | |
return (charToFind + ": " + stream.GetType() + String.Empty + (stream.Position + 512M)) | |
.Where(c=>c == charToFind).ToArray(); | |
} |
This slightly contrived method contains just one C# statement in it, but this statement does an awful lot of work. In fact, here is the Intermediate Language (IL) the C# compiler produced for this method. (I’ve put some lines in boldface italics that are potential points of failure due to implicit operations that are occurring.)
.method private hidebysig static object OneStatement( | |
class [mscorlib]System.IO.Stream stream, char charToFind) cil managed { | |
.maxstack 4 | |
.locals init ( | |
[0] class Program/<>c__DisplayClass1 V_0, | |
[1] object[] V_1) | |
IL_0000: newobj instance void Program/<>c__DisplayClass1::.ctor() | |
IL_0005: stloc.0 | |
IL_0006: ldloc.0 | |
IL_0007: ldarg.1 | |
IL_0008: stfld char Program/<>c__DisplayClass1::charToFind | |
IL_000d: ldc.i4.5 | |
IL_000e: newarr [mscorlib]System.Object | |
IL_0013: stloc.1 | |
IL_0014: ldloc.1 | |
IL_0015: ldc.i4.0 | |
IL_0016: ldloc.0 | |
IL_0017: ldfld char Program/<>c__DisplayClass1::charToFind | |
IL_001c: box [mscorlib]System.Char | |
IL_0021: stelem.ref | |
IL_0022: ldloc.1 | |
IL_0023: ldc.i4.1 | |
IL_0024: ldstr ": " | |
IL_0029: stelem.ref | |
IL_002a: ldloc.1 | |
IL_002b: ldc.i4.2 | |
IL_002c: ldarg.0 | |
IL_002d: callvirt instance class [mscorlib]System.Type [mscorlib]System.Object::GetType() | |
IL_0032: stelem.ref | |
IL_0033: ldloc.1 | |
IL_0034: ldc.i4.3 | |
IL_0035: ldsfld string [mscorlib]System.String::Empty | |
IL_003a: stelem.ref | |
IL_003b: ldloc.1 | |
IL_003c: ldc.i4.4 | |
IL_003d: ldarg.0 | |
IL_003e: callvirt instance int64 [mscorlib]System.IO.Stream::get_Position() | |
IL_0043: call valuetype [mscorlib]System.Decimal | |
[mscorlib]System.Decimal::op_Implicit(int64) | |
IL_0048: ldc.i4 0x200 | |
IL_004d: newobj instance void [mscorlib]System.Decimal::.ctor(int32) | |
IL_0052: call valuetype [mscorlib]System.Decimal [mscorlib]System.Decimal::op_Addition | |
(valuetype [mscorlib]System.Decimal, valuetype [mscorlib]System.Decimal) | |
IL_0057: box [mscorlib]System.Decimal | |
IL_005c: stelem.ref | |
IL_005d: ldloc.1 | |
IL_005e: call string [mscorlib]System.String::Concat(object[]) | |
IL_0063: ldloc.0 | |
IL_0064: ldftn instance bool Program/<>c__DisplayClass1::<OneStatement>b__0(char) | |
IL_006a: newobj instance | |
void [mscorlib]System.Func`2<char, bool>::.ctor(object, native int) | |
IL_006f: call class [mscorlib]System.Collections.Generic.IEnumerable`1<!!0> | |
[System.Core]System.Linq.Enumerable::Where<char>( | |
class [mscorlib]System.Collections.Generic.IEnumerable`1<!!0>, | |
class [mscorlib]System.Func`2<!!0, bool>) | |
IL_0074: call !!0[] [System.Core]System.Linq.Enumerable::ToArray<char> | |
(class [mscorlib]System.Collections.Generic.IEnumerable`1<!!0>) | |
IL_0079: ret | |
} |
As you can see, an OutOfMemoryException is possible when constructing the <>c__DisplayClass1 class (a compiler-generated type), the Object[] array, the Func delegate, and boxing the char and Decimal. Memory is also allocated internally when Concat, Where, and ToArray are called. Constructing the Decimal instance could cause its type constructor to be invoked, resulting in a TypeInitializationException.5 And then, there are the implicit calls to Decimal’s op_Implicit operator and its op_Addition operator methods, which could do anything, including throwing an OverflowException.
Querying Stream’s Position property is interesting. First, it is a virtual property and so my OneStatement method has no idea what code will actually execute which could throw any exception at all. Second, Stream is derived from MarshalByRefObject, so the stream argument could actually refer to a proxy object which itself refers to an object in another AppDomain. The other AppDomain could be unloaded, so an AppDomainUnloadedException could also be thrown here.
Of course, all the methods that are being called are methods that I personally have no control over because they are produced by Microsoft. And it’s entirely possible that Microsoft might change how these methods are implemented in the future, so they could throw new exception types that I could not possibly know about on the day I wrote the OneStatement method. How can I possibly write my OneStatement method to be completely robust against all possible failures? By the way, the opposite is also a problem: a catch block could catch an exception type derived from the specified exception type and now I’m executing recovery code for a different kind of failure.
So now that you have a sense of all the possible failures, you can probably see why it has become culturally acceptable to not write truly robust and reliable code: it is simply impractical. Moreover, one could argue that it is actually impossible. The fact that errors do not occur frequently is another reason why it has become culturally acceptable. Because errors (like OutOfMemoryException) occur very infrequently, the community has decided to trade truly reliable code for programmer productivity.
One of the nice things about exceptions is that an unhandled one causes your application to terminate. This is nice because during testing, you will discover problems quickly and the information you get with an unhandled exception (error message and stack trace) are usually enough to allow you to fix your code. Of course, a lot of companies don’t want their application to just terminate after it has been tested and deployed, so a lot of developers insert code to catch System.Exception, the base class of all exception types. However, the problem with catching System.Exception and allowing the application to continue running is that state may be corrupted.
Earlier in this chapter, I showed an Account class that defines a Transfer method whose job is to transfer money from one account to another account. What if, when this Transfer method is called, it successfully subtracts money from the from account and then throws an exception before it adds money to the to account? If calling code catches System.Exception and continues running, then the state of the application is corrupted: both the from and to accounts have less money in them then they should. Because we are talking about money here, this state corruption wouldn’t just be considered a simple bug, it would definitely be considered a security bug. If the application continues running, it will attempt to perform more transfers to and from various accounts and now state corruption is running rampant within the application.
One could say that the Transfer method itself should catch System.Exception and restore money back into the from account. And this might actually work out OK if the Transfer method is simple enough. But if the Transfer method produces an audit record of the withdrawn money or if other threads are manipulating the same account at the same time, then attempting to undo the operation could fail as well, producing yet another thrown exception. And now, state corruption is getting worse, not better.
💡注意:有人或许会说,知道哪里出错,比知道出了什么错更有用。例如,更有用的是知道从一个账户转账失败,而不是知道 Transfer 由于 SecurityException 或 OutOfMemoryException 而失败。事实上, Win32 错误模型就是这么设计的,方法是返回 true/false 来指明成功 / 失败,使你知道哪个方法失败。然后,如果程序关心失败的原因,可调用 Win32 函数 GetLastError 。 System.Exception 确实有一个 Source 属性可以告诉你失败的方法。但这个属性是一个你必须进行解析的 String ,而且假如两个方法在内部调用同一个方法,那么单凭 Source 属性是看不出哪个方法失败的。相反,必须解析从 Exception 的 StackTrace 属性返回的 String 来获取这个信息。这实在是太难了,我从未见过任何人真的写代码这样做。
There are several things you can do to help mitigate state corruption:
- The CLR doesn’t allow a thread to be aborted when executing code inside a catch or finally block. So, we could make the Transfer method more robust simply by doing the following.
public static void Transfer(Account from, Account to, Decimal amount) { | |
try { /* do nothing in here */ } | |
finally { | |
from -= amount; | |
// Now, a thread abort (due to Thread.Abort/AppDomain.Unload) can’t happen here | |
to += amount; | |
} | |
} |
However, it is absolutely not recommended that you write all your code in finally blocks! You should only use this technique for modifying extremely sensitive state.
You can use the System.Diagnostics.Contracts.Contract class to apply code contracts to your methods. Code contracts give you a way to validate arguments and other variables before you attempt to modify state by using these arguments/variables. If the arguments/ variables meet the contract, then the chance of corrupted state is minimized (not completely eliminated). If a contract fails, then an exception is thrown before any state has been modified. I will talk about code contracts later in this chapter.
You can use constrained execution regions (CERs), which give you a way to take some CLR uncertainty out of the picture. For example, before entering a try block, you can have the CLR load any assemblies needed by code in any associated catch and finally blocks. In addition, the CLR will compile all the code in the catch and finally blocks including all the methods called from within those blocks. This will eliminate a bunch of potential exceptions (including FileLoadException, BadImageFormatException, InvalidProgramException, FieldAccessException, MethodAccessException, MissingFieldException, and MissingMethodException) from occurring when trying to execute error recovery code (in catch blocks) or cleanup code (in the finally block). It will also reduce the potential for OutOfMemoryException and some other exceptions as well. I talk about CERs later in this chapter.
Depending on where the state lives, you can use transactions which ensure that all state is modified or no state is modified. If the data is in a database, for example, transactions work well. Windows also now supports transacted registry and file operations (on an NTFS volume only), so you might be able to use this; however, the .NET Framework doesn’t expose this functionality directly today. You will have to P/Invoke to native code to leverage it. See the System.Transactions.TransactionScope class for more details about this.
You can design your methods to be more explicit. For example, the Monitor class is typically used for taking/releasing a thread synchronization lock as follows.
public static class SomeType { | |
private static Object s_myLockObject = new Object(); | |
public static void SomeMethod () { | |
Monitor.Enter(s_myLockObject); // If this throws, did the lock get taken or | |
// not? If it did, then it won't get released! | |
try { | |
// Do thread-safe operation here... | |
} | |
finally { | |
Monitor.Exit(s_myLockObject); | |
} | |
} | |
// ... | |
} |
Due to the problem just shown, the overload of the preceding Monitor’s Enter method used is now discouraged, and it is recommended that you rewrite the preceding code as follows.
public static class SomeType { | |
private static Object s_myLockObject = new Object(); | |
public static void SomeMethod () { | |
Boolean lockTaken = false; // Assume the lock was not taken | |
try { | |
// This works whether an exception is thrown or not! | |
Monitor.Enter(s_myLockObject, ref lockTaken); | |
// Do thread-safe operation here... | |
} | |
finally { | |
// If the lock was taken, release it | |
if (lockTaken) Monitor.Exit(s_myLockObject); | |
} | |
} | |
// ... | |
} |
Although the explicitness in this code is an improvement, in the case of thread synchronization locks, the recommendation now is to not use them with exception handling at all. See Chapter 30, “Hybrid Thread Synchronization Constructs,” for more details about this.
If, in your code, you have determined that state has already been corrupted beyond repair, then you should destroy any corrupted state so that it can cause no additional harm. Then, restart your application so your state initializes itself to a good condition and hopefully, the state corruption will not happen again. Because managed state cannot leak outside of an AppDomain, you can destroy any corrupted state that lives within an AppDomain by unloading the entire AppDomain by calling AppDomain’s Unload method (see Chapter 22 for details).
And, if you feel that your state is so bad that the whole process should be terminated, then you can call Environment’s static FailFast method.
public static void FailFast(String message); | |
public static void FailFast(String message, Exception exception); |
This method terminates the process without running any active try/finally blocks or Finalize methods. This is good because executing more code while state is corrupted could easily make matters worse. However, FailFast will allow any CriticalFinalizerObject-derived objects, discussed in Chapter 21, “The Managed Heap and Garbage Collection,” a chance to clean up. This is usually OK because they tend to just close native resources, and Windows state is probably fine even if the CLR’s state or your application’s state is corrupted. The FailFast method writes the message string and optional exception (usually the exception captured in a catch block) to the Windows Application event log, produces a Windows error report, creates a memory dump of your application, and then terminates the current process.
💡重要提示:发生意料之外的异常时,Microsoft 的大多数 FCL 代码都不保证状态保持良好。如果你的代码捕捉从 FCL 代码那里 “漏” 过来的异常并继续使用 FCL 的对象,这些对象的行为有可能变得无法预测。令人难堪的是,现在越来越多的 FCL 对象在面对非预期的异常时不能更好地维护状态或者在状态无法恢复时调用 FailFast 。
The point of this discussion is to make you aware of the potential problems related to using the CLR’s exception-handling mechanism. Most applications cannot tolerate running with a corrupted state because it leads to incorrect data and possible security holes. If you are writing an application that cannot tolerate terminating (like an operating system or database engine), then managed code is not a good technology to use. And although Microsoft Exchange Server is largely written in managed code, it uses a native database to store email messages. The native database is called the Extensible Storage Engine; it ships with Windows, and can usually be found at C:\Windows\System32\EseNT.dll. Your applications can also use this engine if you’d like; search for “Extensible Storage Engine” on the Microsoft MSDN website.
Managed code is a good choice for applications that can tolerate an application terminating when state corruption has possibly occurred. There are many applications that fall into this category. Also, it takes significantly more resources and skills to write a robust native class library or application; for many applications, managed code is the better choice because it greatly enhances programmer productivity.
💡小结:为何不去追求完全健壮和可靠的代码:因为不切实际(更极端的说法是根本不可能)。不去追求完全的健壮性和可靠性,另一个原因是错误不经常发生。由于错误(比如 OutOfMemoryException )及其罕见,所以开发人员决定不去追求完全可靠的代码,牺牲一定的可靠性来换取程序员开发效率的提升。异常的好处在于,未处理的异常会造成应用程序终止。之所以是好事,是因为可在测试期间提早发现问题。利用由未处理异常提供的信息(错误信息和堆栈追踪),通常足以完成对代码的修正。当然,许多公司不希望应用程序在测试和部署之后还发生意外终止的情况,所以会插入代码来捕捉 System.Exception ,也就是所有异常类型的基类。但如果捕捉 System.Exception 并允许应用程序继续运行,一个很大的问题是状态可能遭受破坏。执行 catch 或 finally 块中的代码时,CLR 不允许线程终止。但绝对不建议将所有代码都放到 finally 块中!这个技术只适合修改极其敏感的状态。可以用 System.Diagnostics.Contrancts.Contract 类向方法应用代码协定。通过代码协定,在用实参和其他变量对状态进行修改之前,可以先对这些实参 / 变量进行验证。如果实参 / 变量遵守协定,状态被破坏的可能性将大幅降低 (但不能完全消除)。如果不遵守协定,那么异常会在任何状态被修改之前抛出。可以使用约束执行区域 (Constrained Execution Region,CER),它能消除 CLR 的某些不确定性。取决于状态存在于何处,可利用事务 (transaction) 来确保状态要么都修改,要么都不修改。在你的代码中,如果确定状态已损坏到无法修复的程度,就应销毁所有损坏的状态,防止它造成更多的伤害。然后,重新启动应用程序,将状态初始化到良好状态,并寄希望于状态不再损坏。由于托管的状态泄露不到 AppDomain 的外部,所以为了销毁 AppDomain 中所有损坏的状态,可调用 AppDomain 的 Unload 方法来卸载整个 AppDomain。如果觉得状态过于糟糕,以至于整个进程都应该终止,那么应该调用 Environment 的静态 FailFast 方法。这个方法在终止进程时,不会运行任何活动的 try/finally 块或者 Finalize 方法。之所以这样做,是因为在状态已损坏的前提下执行更多的代码,很容易使局面变得更坏。不过, FailFast 为从 CriticalFinalizerObject 派生的任何对象提供了进行清理的机会,因为它们一般只是关闭本机资源;而即使 CLR 或者你的应用程序的状态发生损坏,Windows 状态也可能是好的。 FailFast 方法将消息字符串和可选的异常 (通常是 catch 块中捕捉的异常) 写入 Windows Application 事件日志,生成 Windows 错误报告,创建应用程序的内存转储 (dump),然后终止当前进程。大多数应用程序都不能容忍状态受损而继续运行,因为这可能造成不正确的数据,设置可能造成安全漏洞。如果应用程序不方便终止 (比如操作系统或数据库引擎),托管代码就不是一个好的技术。如果应用程序 “在状态可能损坏时终止” 不会造成严重后果,就适合用托管代码来写。有许多应用程序都满足这个要求。此外,需要多得多的资源和技能,才能写出健壮的本机 (native) 类库或应用程序。对于许多应用程序,托管代码是更好的选择,因为它极大提升了开发效率。
# Guidelines and Best Practices
Understanding the exception mechanism is certainly important. It is equally important to understand how to use exceptions wisely. All too often, I see library developers catching all kinds of exceptions, preventing the application developer from knowing that a problem occurred. In this section, I offer some guidelines for developers to be aware of when using exceptions.
💡重要提示:如果你是类库开发人员,要设计供其他开发人员使用的类型,那么一定要严格按照这些规范行事,你的责任很重大,要精心设计类库中的类型,那么一定要更严格按照这些规范行事。你的责任很重大,要精心设计类库中的类型,使之适用于各种各样的应用程序。记住,你无法做到对要回调的代码 (通过委托、虚方法或接口方法) 了如指掌,也不知道哪些代码会调用你 (的代码)。由于无法预知使用类型的每一种情形,所以不要做出任何策略抉择 (遇见到具体异常并相应处理)。换言之,你的代码一定不能想当然地决定一些错误情形;应该让调用者自己决定。
此外,要严密监视状态,尽量不要破坏它。使用代码协定 (本章稍后讨论) 验证传给方法的实参。尝试完全不去修改状态。如果不得不修改状态,就做好出错的准备,并在出错后尝试恢复状态。遵照本章的设计规范行事,应用程序的开发人员就可以顺畅地使用你的类库中的类型。
如果你是应用程序开发人员,可定义自己认为合适的任何策略,按照本章的规范行事,有助于在应用程序发布前发现并修复代码中的问题,使应用程序更健壮,但经深思熟虑之后,也可以不按这些规范行事。你要设置自己的策略。例如,应用程序代码在捕捉异常方面可以比类库代码更激进一些。
# Use finally Blocks Liberally
I think finally blocks are awesome! They allow you to specify a block of code that’s guaranteed to execute no matter what kind of exception the thread throws. You should use finally blocks to clean up from any operation that successfully started before returning to your caller or allowing code following the finally block to execute. You also frequently use finally blocks to explicitly dispose of any objects to avoid resource leaking. Here’s an example that has all cleanup code (closing the file) in a finally block.
using System; | |
using System.IO; | |
public sealed class SomeType { | |
private void SomeMethod() { | |
FileStream fs = new FileStream(@"C:\Data.bin ", FileMode.Open); | |
try { | |
// Display 100 divided by the first byte in the file. | |
Console.WriteLine(100 / fs.ReadByte()); | |
} | |
finally { | |
// Put cleanup code in a finally block to ensure that the file gets closed regardless | |
// of whether or not an exception occurs (for example, the first byte was 0). | |
if (fs != null) fs.Dispose(); | |
} | |
} | |
} |
Ensuring that cleanup code always executes is so important that many programming languages offer constructs that make writing cleanup code easier. For example, the C# language automatically emits try/finally blocks whenever you use the lock, using, and foreach statements. The C# compiler also emits try/finally blocks whenever you override a class’s destructor (the Finalize method). When using these constructs, the compiler puts the code you’ve written inside the try block and automatically puts the cleanup code inside the finally block. Specifically:
When you use the lock statement, the lock is released inside a finally block.
When you use the using statement, the object has its Dispose method called inside a finally block.
When you use the foreach statement, the IEnumerator object has its Dispose method called inside a finally block.
When you define a destructor method, the base class’s Finalize method is called inside a finally block.
For example, the following C# code takes advantage of the using statement. This code is shorter than the code shown in the previous example, but the code that the compiler generates is identical to the code generated in the previous example.
using System; | |
using System.IO; | |
internal sealed class SomeType { | |
private void SomeMethod() { | |
using (FileStream fs = new FileStream(@"C:\Data.bin", FileMode.Open)) { | |
// Display 100 divided by the first byte in the file. | |
Console.WriteLine(100 / fs.ReadByte()); | |
} | |
} | |
} |
For more about the using statement, see Chapter 21; and for more about the lock statement, see Chapter 30.
# Don’t Catch Everything
A ubiquitous mistake made by developers who have not been properly trained on the proper use of exceptions is to use catch blocks too often and improperly. When you catch an exception, you’re stating that you expected this exception, you understand why it occurred, and you know how to deal with it. In other words, you’re defining a policy for the application. This all goes back to the “Trading Reliability for Productivity“ section earlier in this chapter.
All too often, I see code like this.
try { | |
// try to execute code that the programmer knows might fail... | |
} | |
catch (Exception) { | |
... | |
} |
This code indicates that it was expecting any and all exceptions and knows how to recover from any and all situations. How can this possibly be? A type that’s part of a class library should never, ever, under any circumstance catch and swallow all exceptions because there is no way for the type to know exactly how the application intends to respond to an exception. In addition, the type will frequently call out to application code via a delegate, virtual method, or interface method. If the application code throws an exception, another part of the application is probably expecting to catch this exception. The exception should be allowed to filter its way up the call stack and let the application code handle the exception as it sees fit.
If the exception is unhandled, the CLR terminates the process. I’ll discuss unhandled exceptions later in this chapter. Most unhandled exceptions will be discovered during testing of your code. To fix these unhandled exceptions, you will either modify the code to look for a specific exception, or you will rewrite the code to eliminate the conditions that cause the exception to be thrown. The final version of the code that will be running in a production environment should see very few unhandled exceptions and will be extremely robust.
💡注意:有时,不能完成任务的一个方法检测到对象状态已经损坏,而且状态无法恢复。假如允许应用程序继续运行,可能造成不可预测的行为或安全隐患。检测到这种情况,方法不应抛出异常。相反,应调用 System.Environment 的 FailFast 方法强迫进程终止。
By the way, it is OK to catch System.Exception and execute some code inside the catch block’s braces as long as you re-throw the exception at the bottom of that code. Catching System.Exception and swallowing the exception (not re-throwing it) should never be done because it hides failures that allow the application to run with unpredictable results and potential security vulnerabilities. Visual Studio’s code analysis tool (FxCopCmd.exe) will flag any code that contains a catch (Exception) block unless there is a throw statement included in the block’s code. The “Backing Out of a Partially Completed Operation When an Unrecoverable Exception Occurs—Maintaining State” section, coming shortly in this chapter, will discuss this pattern.
Finally, it is OK to catch an exception occurring in one thread and re-throw the exception in another thread. The Asynchronous Programming Model (discussed in Chapter 28, “I/O-Bound Asynchronous Operations”) supports this. For example, if a thread pool thread executes code that throws an exception, the CLR catches and swallows the exception and allows the thread to return to the thread pool. Later, a thread should call an EndXxx method to determine the result of the asynchronous operation. The EndXxx method will throw the same exception object that was thrown by the thread pool thread that did the actual work. In this scenario, the exception is being swallowed by the first thread; however, the exception is being re-thrown by the thread that called the EndXxx method, so it is not being hidden from the application.
# Recovering Gracefully from an Exception
Sometimes you call a method knowing in advance some of the exceptions that the method might throw. Because you expect these exceptions, you might want to have some code that allows your application to recover gracefully from the situation and continue running. Here’s an example in pseudocode.
public String CalculateSpreadsheetCell(Int32 row, Int32 column) { | |
String result; | |
try { | |
result = /* Code to calculate value of a spreadsheet's cell */ | |
} | |
catch (DivideByZeroException) { | |
result = "Can't show value: Divide by zero"; | |
} | |
catch (OverflowException) { | |
result = "Can't show value: Too big"; | |
} | |
return result; | |
} |
This pseudocode calculates the contents of a cell in a spreadsheet and returns a string representing the value to the caller so that the caller can display the string in the application’s window. However, a cell’s contents might be the result of dividing one cell by another cell. If the cell containing the denominator contains 0, the CLR will throw a DivideByZeroException object. In this case, the method catches this specific exception and returns a special string that will be displayed to the user. Similarly, a cell’s contents might be the result of multiplying one cell by another. If the multiplied value doesn’t fit in the number of bits allowed, the CLR will throw an OverflowException object, and again, a special string will be displayed to the user.
When you catch specific exceptions, fully understand the circumstances that cause the exception to be thrown, and know what exception types are derived from the exception type you’re catching. Don’t catch and handle System.Exception (without re-throwing) because it’s not feasible for you to know all of the possible exceptions that could be thrown within your try block (especially if you consider the OutOfMemoryException or the StackOverflowException, to name two).
# Backing Out of a Partially Completed Operation When an Unrecoverable Exception Occurs—Maintaining State
Usually, methods call several other methods to perform a single abstract operation. Some of the individual methods might complete successfully, and some might not. For example, let’s say that you’re serializing a set of objects to a disk file. After serializing 10 objects, an exception is thrown. (Perhaps the disk is full or the next object to be serialized isn’t marked with the Serializable custom attribute.) At this point, the exception should filter up to the caller, but what about the state of the disk file? The file is now corrupted because it contains a partially serialized object graph. It would be great if the application could back out of the partially completed operation so that the file would be in the state it was in before any objects were serialized into it. The following code demonstrates the correct way to implement this.
public void SerializeObjectGraph(FileStream fs, IFormatter formatter, Object rootObj) { | |
// Save the current position of the file. | |
Int64 beforeSerialization = fs.Position; | |
try { | |
// Attempt to serialize the object graph to the file. | |
formatter.Serialize(fs, rootObj); | |
} | |
catch { // Catch any and all exceptions. | |
// If ANYTHING goes wrong, reset the file back to a good state. | |
fs.Position = beforeSerialization; | |
// Truncate the file. | |
fs.SetLength(fs.Position); | |
// NOTE: The preceding code isn't in a finally block because | |
// the stream should be reset only when serialization fails. | |
// Let the caller(s) know what happened by re-throwing the SAME exception. | |
throw; | |
} | |
} |
To properly back out of the partially completed operation, write code that catches all exceptions. Yes, catch all exceptions here because you don’t care what kind of error occurred; you need to put your data structures back into a consistent state. After you’ve caught and handled the exception, don’t swallow it—let the caller know that the exception occurred. You do this by re-throwing the same exception. In fact, C# and many other languages make this easy. Just use C#’s throw keyword without specifying anything after throw, as shown in the previous code.
Notice that the catch block in the previous example doesn’t specify any exception type because I want to catch any and all exceptions. In addition, the code in the catch block doesn’t need to know exactly what kind of exception was thrown, just that something went wrong. Fortunately, C# lets me do this easily just by not specifying any exception type and by making the throw statement re-throw whatever object is caught.
# Hiding an Implementation Detail to Maintain a “Contract”
In some situations, you might find it useful to catch one exception and re-throw a different exception. The only reason to do this is to maintain the meaning of a method’s contract. Also, the new exception type that you throw should be a specific exception (an exception that’s not used as the base type of any other exception type). Imagine a PhoneBook type that defines a method that looks up a phone number from a name, as shown in the following pseudocode.
internal sealed class PhoneBook { | |
private String m_pathname; // path name of file containing the address book | |
// Other methods go here. | |
public String GetPhoneNumber(String name) { | |
String phone; | |
FileStream fs = null; | |
try { | |
fs = new FileStream(m_pathname, FileMode.Open); | |
// Code to read from fs until name is found goes here | |
phone = /* the phone # found */ | |
} | |
catch (FileNotFoundException e) { | |
// Throw a different exception containing the name, and | |
// set the originating exception as the inner exception. | |
throw new NameNotFoundException(name, e); | |
} | |
catch (IOException e) { | |
// Throw a different exception containing the name, and | |
// set the originating exception as the inner exception. | |
throw new NameNotFoundException(name, e); | |
} | |
finally { | |
if (fs != null) fs.Close(); | |
} | |
return phone; | |
} | |
} |
The phone book data is obtained from a file (versus a network connection or database). However, the user of the PhoneBook type doesn’t know this because this is an implementation detail that could change in the future. So if the file isn’t found or can’t be read for any reason, the caller would see a FileNotFoundException or IOException, which wouldn’t be anticipated. In other words, the file’s existence and ability to be read is not part of the method’s implied contract: there is no way the caller could have guessed this. So the GetPhoneNumber method catches these two exception types and throws a new NameNotFoundException.
When using this technique, you should catch specific exceptions that you fully understand the circumstances that cause the exception to be thrown. And, you should also know what exception types are derived from the exception type you’re catching.
Throwing an exception still lets the caller know that the method cannot complete its task, and the NameNotFoundException type gives the caller an abstracted view as to why. Setting the inner exception to FileNotFoundException or IOException is important so that the real cause of the exception isn’t lost. Besides, knowing what caused the exception could be useful to the developer of the PhoneBook type and possibly to a developer using the PhoneBook type.
💡重要提示:使用这个技术时,实际是在两个方面欺骗了调用者。首先,在实际发生的错误上欺骗了调用者。本例是文件未找到,而报告的是没有找到指定的姓名。其次,在错误发生的位置上欺骗了调用者。如果允许 FileNotFoundException 异常在掉应该能栈中向上传递,它的 StackTrace 属性显示错误在 FileStream 的构造器发生。但由于现在是 “吞噬” 该异常并重新抛出新的 NameNotFoundException 异常,所以堆栈跟踪会显示错误在 catch 块中发生,离异常实际发生的位置有好几行远。这会使调试变得困难。所以,这个技术务必慎用。
Now let’s say that the PhoneBook type was implemented a little differently. Assume that the type offers a public PhoneBookPathname property that allows the user to set or get the path name of the file in which to look up a phone number. Because the user is aware of the fact that the phone book data comes from a file, I would modify the GetPhoneNumber method so that it doesn’t catch any exceptions; instead, I let whatever exception is thrown propagate out of the method. Note that I’m not changing any parameters of the GetPhoneNumber method, but I am changing how it’s abstracted to users of the PhoneBook type. Users now expect a path to be part of the PhoneBook’s contract.
Sometimes developers catch one exception and throw a new exception in order to add additional data or context to an exception. However, if this is all you want to do, you should just catch the exception type you want, add data to the exception object’s Data property collection, and then re-throw the same exception object.
private static void SomeMethod(String filename) { | |
try { | |
// Do whatevere here... | |
} | |
catch (IOException e) { | |
// Add the filename to the IOException object | |
e.Data.Add("Filename", filename); | |
throw; // re-throw the same exception object that now has additional data in it | |
} | |
} |
Here is a good use of this technique: when a type constructor throws an exception that is not caught within the type constructor method, the CLR internally catches that exception and throws a new TypeInitializationException instead. This is useful because the CLR emits code within your methods to implicitly call type constructors.6 If the type constructor threw a DivideByZeroException, your code might try to catch it and recover from it but you didn’t even know you were invoking the type constructor. So the CLR converts the DivideByZeroException into a TypeInitializationException so that you know clearly that the exception occurred due to a type constructor failing; the problem wasn’t with your code.
On the other hand, here is a bad use of this technique: when you invoke a method via reflection, the CLR internally catches any exception thrown by the method and converts it to a TargetInvocationException. This is incredibly annoying because you must now catch the TargetInvocationException object and look at its InnerException property to discern the real reason for the failure. In fact, when using reflection, it is common to see code that looks like this.
private static void Reflection(Object o) { | |
try { | |
// Invoke a DoSomething method on this object | |
var mi = o.GetType().GetMethod("DoSomething"); | |
mi.Invoke(o, null); // The DoSomething method might throw an exception | |
} | |
catch (System.Reflection.TargetInvocationException e) { | |
// The CLR converts reflection-produced exceptions to TargetInvocationException | |
throw e.InnerException; // Re-throw what was originally thrown | |
} | |
} |
I have good news though: if you use C#’s dynamic primitive type (discussed in Chapter 5, “Primitive, Reference, and Value Types”) to invoke a member, the compiler-generated code does not catch any and all exceptions and throw a TargetInvocationException object; the originally thrown exception object simply walks up the stack. For many developers, this is a good reason to prefer using C#’s dynamic primitive type rather than reflection.
💡小结:确保清理代码的执行时如此重要,以至于许多编程语言都提供了一些构造来简化这种代码的编写。例如,只要使用了 lock , using 和 foreach 语句,C# 编译器就会自动生成 try/finally 块,另外,重写类的析构器 ( Finalize 方法) 时,C# 编译器也会自动生成 try/finally 块。使用这些构造时,编译器将你写的代码放到 try 块内部,并将清理代码放到 finally 块中。如果类型是类库的一部分,那么任何情况下都绝对不允许捕捉并 “吞噬” 所有异常,因为它不可能准确预知应用程序将如何响应一个异常。此外,类型经常通过委托、虚方法或接口方法调用应用程序代码。应用程序代码抛出异常,应用程序的另一部分可能预期要捕捉该异常。所以,绝对不要写 “大小通吃” 的类型,悄悄地 “吞噬” 异常,而是应该允许异常在调用栈中向上移动,让应用程序代码针对性地处理它。如果异常未得到处理,CLR 会终止进程。大多数未处理异常都能在代码测试期间发现。为了修正这些未处理的异常,要么修改代码来捕捉特定异常,要么重写代码排除会造成异常的出错条件。在生产环境中运行的最终版本应该极少出现未处理的异常,而且应该相当健壮。可以在一个线程中捕捉异常,在另一个线程中重新抛出异常。为此提供支持的是异步编程模型。为了正确回滚已部分完成的操作,代码应捕捉所有异常。是的,这里要捕捉所有异常,因为你不关心发生了什么错误,只关心如何将数据结构恢复为一致状态。捕捉并处理好异常后,不要把它 “吞噬”(假装它没有发生)。相反,要让调用者知道发生了异常。为此,只需重新抛出相同的异常。事实上,C# 和许多其他语言都简化了这项任务,只需像上述代码那样单独使用 C# 的 throw 关键字,不在 throw 后指定任何东西。有时,开发人员之所以捕捉一个异常并抛出一个新异常,目的是在异常中添加额外的数据或上下文。然而,如果这是你唯一的目的,那么只需捕捉希望的异常类型,在异常对象的 Data 属性 (一个键 / 值对的集合) 中添加数据,然后重新抛出相同的异常对象。使用 C# 的 dynamic 基元类型来调用成员,最初抛出的异常对象会正常地在调用栈中向上传递。对于大多数开发人员,这是使用 C# 的 dynamic 基元类型来代替反射的一个很好的理由。
# Unhandled Exceptions
When an exception is thrown, the CLR climbs up the call stack looking for catch blocks that match the type of the exception object being thrown. If no catch block matches the thrown exception type, an unhandled exception occurs. When the CLR detects that any thread in the process has had an unhandled exception, the CLR terminates the process. An unhandled exception identifies a situation that the application didn’t anticipate and is considered to be a true bug in the application. At this point, the bug should be reported back to the company that publishes the application. Hopefully, the publisher will fix the bug and distribute a new version of the application.
Class library developers should not even think about unhandled exceptions. Only application developers need to concern themselves with unhandled exceptions, and the application should have a policy in place for dealing with unhandled exceptions. Microsoft actually recommends that application developers just accept the CLR’s default policy. That is, when an application gets an unhandled exception, Windows writes an entry to the system’s event log. You can see this entry by opening the Event Viewer application and then looking under the Windows Logs ➔ Application node in the tree, as shown in Figure 20-1.
FIGURE 20-1 Windows Event log showing an application that terminated due to an unhandled exception.
However, you can get more interesting details about the problem by using the Windows Reliability Monitor applet. To start Reliability Monitor, open the Windows Control Panel and search for “reliability history”. From here, you can see the applications that have terminated due to an unhandled exception in the bottom pane, as shown in Figure 20-2.
FIGURE 20-2 Reliability Monitor showing an application that terminated due to an unhandled exception.
To see more details about the terminated application, double-click a terminated application in Reliability Monitor. The details will look something like Figure 20-3 and the meaning of the problem signatures are described in Table 20-2. All unhandled exceptions produced by managed applications are placed in the CLR20r3 bucket.
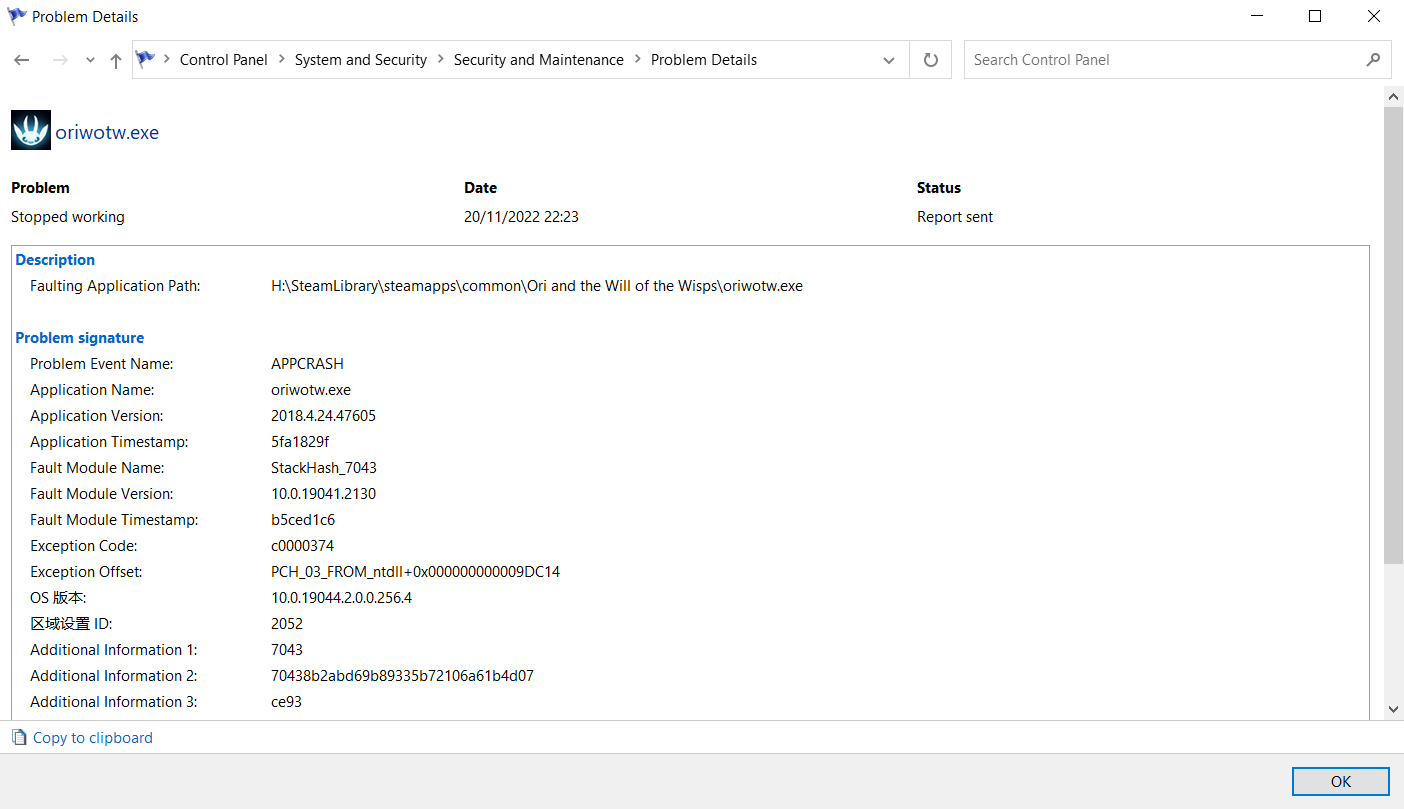
FIGURE 20-3 Reliability Monitor showing more details about the failed application.

After recording information about the failing application, Windows displays the message box allowing the end user to send information about the failing application to Microsoft servers.7 This is called Windows Error Reporting, and more information about it can be found at the Windows Quality website (http://WinQual.Microsoft.com).
Companies can optionally sign up with Microsoft to view this information about their own applications and components. Signing up is free, but it does require that your assemblies be signed with a VeriSign ID (also called a Software Publisher’s Digital ID for Authenticode).
Naturally, you could also develop your own system for getting unhandled exception information back to you so that you can fix bugs in your code. When your application initializes, you can inform the CLR that you have a method that you want to be called whenever any thread in your application experiences an unhandled exception.
Unfortunately, every application model Microsoft produces has its own way of tapping into unhandled exceptions. The members that you want to look up in the FCL documentation are.
For many applications, look at System.AppDomain’s UnhandledException event. Windows Store applications and Microsoft Silverlight applications cannot access this event. 4
For a Windows Store App, look at Windows.UI.Xaml.Application’s UnhandledException event.
For a Windows Forms application, look at System.Windows.Forms.NativeWindow’s OnThreadException virtual method, System.Windows.Forms.Application’s OnThreadException virtual method, and System.Windows.Forms.Application’s ThreadException event.
For a Windows Presentation Foundation (WPF) application, look at System.Windows. Application’s DispatcherUnhandledException event and System.Windows. Threading.Dispatcher’s UnhandledException and UnhandledExceptionFilter events.
For Silverlight, look at System.Windows.Application’s UnhandledException event.
For an ASP.NET Web Form application, look at System.Web.UI.TemplateControl’s Error event. TemplateControl is the base class of the System.Web.UI.Page and System.Web.UI.UserControl classes. Furthermore, you should also look at System. Web.HttpApplication’s Error event.
For a Windows Communication Foundation application, look at System.ServiceModel. Dispatcher.ChannelDispatcher’s ErrorHandlers property.
Before I leave this section, I’d like to say a few words about unhandled exceptions that could occur in a distributed application such as a website or web service. In an ideal world, a server application that experiences an unhandled exception should log it, send some kind of notification back to the client indicating that the requested operation could not complete, and then the server should terminate. Unfortunately, we don’t live in an ideal world, and therefore, it may not be possible to send a failure notification back to the client. For some stateful servers (such as Microsoft SQL Server), it may not be practical to terminate the server and start a brand new instance.
For a server application, information about the unhandled exception should not be returned to the client because there is little a client could do about it, especially if the client is implemented by a different company. Furthermore, the server should divulge as little information about itself as possible to its clients to reduce that potential of the server being hacked.
💡注意:CLR 认为本机代码 (native code) 抛出的一些异常时损坏状态异常 (corrupted state exceptions, CSE) 异常,因为它们一般由 CLR 自身的 bug 造成,或者由托管开发人员无法控制的本机代码的 bug 造成。CLR 默认不让托管代码捕捉这些异常, finally 块也不会执行。以下本机 Win32 异常被认为是 CSE:
EXCEPTION_ACCESS_VIOLATION EXCEPTION_STACK_OVERFLOW | |
EXCEPTION_ILLEGAL_INSTRUCTION EXCEPTION_IN_PAGE_ERROR | |
EXCEPTION_INVALID_DISPOSITION EXCEPTION_NONCONTINUABLE_EXCEPTION | |
EXCEPTION_PRIV_INSTRUCTION STATUS_UNWIND_CONSOLIDATE. |
但是,单独的托管方法可以覆盖默认设置来捕捉这些异常,这需要向方法应用 System.Runtime.ExceptionServices.HandleProcessCorruptedStateExceptionsAttribute 。方法还要应用 System.Security.SecurityCriticalAttribute 。要覆盖整个进程的默认设置,可在应用程序的 XML 配置文件中将 legacyCorruptedStateExceptionPolicy 元素设为 true 。CLR 将上述大多数异常都转换成一个 System.Runtime.InteropServices.SEHException 对象,但有两个异常例外: EXCEPTION_ACCESS_VIOLATION 被转换成 System.AccessViolationException 对象, EXCEPTION_STACK_OVERFLOW 被转换成 System.StackOverflowException 对象。
💡注意:调用方法前,可调用 RuntimeHelper 类的 EnsureSufficientExecutionStack 检查栈空间是否够用。该方法检查调用线程是否有足够的栈空间来执行一般性的方法 (定义得比较随便的方法)。栈空间不够,方法会抛出一个 InsufficientExecutionStackException ,你可以捕捉这个异常。 EnsureSufficientExecutionStack 方法不接受任何实参,返回值是 void 。 递归方法特别要用好这个方法。
💡小结:异常抛出时,CLR 在调用栈中向上查找与抛出的异常对象的类型匹配的 catch 块。没有任何 catch 块匹配抛出的异常类型,就发生一个未处理的异常。应用程序发生未处理的异常时,Windows 会向事件日志写一条记录。记录好出错的应用程序有关的信息后,Windows 显示一个消息框,允许用户将与出错的应用程序有关的信息发送给 Microsoft 的服务器。这称为 “Windows 错误报告”(Windows Error Reporting)。作为公司,可以向 Microsoft 注册查看与它们自己的应用程序和组件有关的信息。注册是免费的,但要求程序集用 VeriSign ID (也称为 Software Publisher Digital ID for Authenticode) 进行签名。当然也可以开发自己的系统,将未处理异常的信息传回给你自己,以便修正代码中的 bug。应用程序初始化时,可告诉 CLR 当应用程序中的任何线程发生一个未处理的异常时,都调用一个方法。最后讲一下分布式应用程序 (例如 Web 站点或 Web 服务) 中发生的未处理异常。理想情况下,服务器应用程序发生未处理异常,应该先把它记录到日志中,再向客户端发送通知,表明所请求的操作无法完成,最后终止服务器应用程序。遗憾的是,我们并非生活在理想世界中。因此,也许不可能向客户端发送失败通知。对于某些 “有状态” 的服务器 (比如 Microsoft SQL Server),终止服务器并重新启动服务器的新实例是不切实际的。对于服务器应用程序,与未处理异常有关的信息不应返回客户端,因为客户端对这种信息基本上是束手无策的,尤其是假如客户端由不同的公司实现。另外,服务器应尽量少暴露自己的相关信息,减少自己被 “黑” 的几率。
# Debugging Exceptions
The Visual Studio debugger offers special support for exceptions. With a solution open, choose Exceptions from the Debug menu, and you’ll see the dialog box shown in Figure 20-4.
FIGURE 20-4 The Exceptions dialog box, showing the different kinds of exceptions.
This dialog box shows the different kinds of exceptions that Visual Studio is aware of. For Common Language Runtime Exceptions, expanding the corresponding branch in the dialog box, as in Figure 20-5, shows the set of namespaces that the Visual Studio debugger is aware of.
FIGURE 20-5 The Exceptions dialog box, showing CLR exceptions by namespace.
If you expand a namespace, you’ll see all of the System.Exception-derived types defined within that namespace. For example, Figure 20-6 shows what you’ll see if you open the System namespace.
For any exception type, if its Thrown check box is selected, the debugger will break as soon as that exception is thrown. At this point, the CLR has not tried to find any matching catch blocks. This is useful if you want to debug your code that catches and handles an exception. It is also useful when you suspect that a component or library may be swallowing or re-throwing exceptions, and you are uncertain where exactly to set a break point to catch it in the act.
FIGURE 20-6 The Exceptions dialog box, showing CLR exceptions defined in the System namespace.
If an exception type’s Thrown check box is not selected, the debugger will also break where the exception was thrown, but only if the exception type was not handled. Developers usually leave the Thrown check box cleared because a handled exception indicates that the application anticipated the situation and dealt with it; the application continues running normally.
If you define your own exception types, you can add them to this dialog box by clicking Add. This causes the dialog box in Figure 20-7 to appear.
FIGURE 20-7 Making Visual Studio aware of your own exception type: the New Exception dialog box.
In this dialog box, you first select the type of exception to be Common Language Runtime Exceptions, and then you can enter the fully qualified name of your own exception type. Note that the type you enter doesn’t have to be a type derived from System.Exception; non–CLS-compliant types are fully supported. If you have two or more types with the same name but in different assemblies, there is no way to distinguish the types from one another. Fortunately, this situation rarely happens.
If your assembly defines several exception types, you must add them one at a time. In the future, I’d like to see this dialog box allow me to browse for an assembly and automatically import all Exception-derived types into Visual Studio’s debugger. Each type could then be identified by assembly as well, which would fix the problem of having two types with the same name in different assemblies.
💡小结:对于任何异常类型,如果勾选了 “引发” 选项框,调试器就会在抛出该异常时中断。注意在中断时,CLR 还没有尝试去查找任何匹配的 catch 块。要对捕捉和处理一个异常的代码进行调试,这个功能相当有用。另外,如果怀疑一个组件或库 “吞噬” 了异常或者重新抛出了异常,但不确定在什么位置设置断点来捕捉它,这个功能也很有用。如果异常类型的 “引发” 框没有勾选,调试器只有在该异常类型未得到处理时才中断。开发人员一般都保持 “引发” 选项框的未勾选状态,因为的到处理的异常表明应用程序已预见到了异常,并会对它进行处理;应用程序能继续正常运行。
# Exception-Handling Performance Considerations
The developer community actively debates the performance of exception handling. Some people claim that exception handling performance is so bad that they refuse to even use exception handling. However, I contend that in an object-oriented platform, exception handling is not an option; it is mandatory. And besides, if you didn’t use it, what would you use instead? Would you have your methods return true/false to indicate success/failure or perhaps some error code enum type? Well, if you did this, then you have the worst of both worlds: the CLR and the class library code will throw exceptions and your code will return error codes. You’d have to now deal with both of these in your code.
It’s difficult to compare performance between exception handling and the more conventional means of reporting exceptions (such as HRESULTs, special return codes, and so forth). If you write code to check the return value of every method call and filter the return value up to your own callers, your application’s performance will be seriously affected. But performance aside, the amount of additional coding you must do and the potential for mistakes is incredibly high when you write code to check the return value of every method. Exception handling is a much better alternative.
However, exception handling has a price: unmanaged C++ compilers must generate code to track which objects have been constructed successfully. The compiler must also generate code that, when an exception is caught, calls the destructor of each successfully constructed object. It’s great that the compiler takes on this burden, but it generates a lot of bookkeeping code in your application, adversely affecting code size and execution time.
On the other hand, managed compilers have it much easier because managed objects are allocated in the managed heap, which is monitored by the garbage collector. If an object is successfully constructed and an exception is thrown, the garbage collector will eventually free the object’s memory. Compilers don’t need to emit any bookkeeping code to track which objects are constructed successfully and don’t need to ensure that a destructor has been called. Compared to unmanaged C++, this means that less code is generated by the compiler, and less code has to execute at run time, resulting in better performance for your application.
Over the years, I’ve used exception handling in different programming languages, different operating systems, and different CPU architectures. In each case, exception handling is implemented differently with each implementation having its pros and cons with respect to performance. Some implementations compile exception handling constructs directly into a method, whereas other implementations store information related to exception handling in a data table associated with the method—this table is accessed only if an exception is thrown. Some compilers can’t inline methods that contain exception handlers, and some compilers won’t enregister variables if the method contains exception handlers.
The point is that you can’t determine how much additional overhead is added to an application when using exception handling. In the managed world, it’s even more difficult to tell because your assembly’s code can run on any platform that supports the .NET Framework. So the code produced by the JIT compiler to manage exception handling when your assembly is running on an x86 machine will be very different from the code produced by the JIT compiler when your code is running on an x64 or ARM processor. Also, JIT compilers associated with other CLR implementations (such as Microsoft’s .NET Compact Framework or the open-source Mono project) are likely to produce different code.
Actually, I’ve been able to test some of my own code with a few different JIT compilers that Microsoft has internally, and the difference in performance that I’ve observed has been quite dramatic and surprising. The point is that you must test your code on the various platforms that you expect your users to run on, and make changes accordingly. Again, I wouldn’t worry about the performance of using exception handling; the benefits typically far outweigh any negative performance impact.
If you’re interested in seeing how exception handling impacts the performance of your code, you can use the Performance Monitor tool that comes with Windows. The screen in Figure 20-8 shows the exception-related counters that are installed along with the .NET Framework.
Occasionally, you come across a method that you call frequently that has a high failure rate. In this situation, the performance hit of having exceptions thrown can be intolerable. For example, Microsoft heard back from several customers who were calling Int32’s Parse method, frequently passing in data entered from an end user that could not be parsed. Because Parse was called frequently, the performance hit of throwing and catching the exceptions was taking a large toll on the application’s overall performance.
FIGURE 20-8 Performance Monitor showing the .NET CLR Exceptions counters.
To address customers’ concerns and to satisfy all the guidelines described in this chapter, Microsoft added a new method to the Int32 class. This new method is called TryParse, and it has two overloads that look like the following.
public static Boolean TryParse(String s, out Int32 result); | |
public static Boolean TryParse(String s, NumberStyles styles, | |
IFormatProvider, provider, out Int32 result); |
You’ll notice that these methods return a Boolean that indicates whether the String passed in contains characters that can be parsed into an Int32. These methods also return an output parameter named result. If the methods return true, result will contain the result of parsing the string into a 32-bit integer. If the methods return false, result will contain 0, but you really shouldn’t execute any code that looks at it anyway.
One thing I want to make absolutely clear: A TryXxx method’s Boolean return value returns false to indicate one and only one type of failure. The method should still throw exceptions for any other type of failure. For example, Int32’s TryParse throws an ArgumentException if the style’s argument is not valid, and it is certainly still possible to have an OutOfMemoryException thrown when calling TryParse.
I also want to make it clear that object-oriented programming allows programmers to be productive. One way that it does this is by not exposing error codes in a type’s members. In other words, constructors, methods, properties, etc. are all defined with the idea that calling them won’t fail. And, if defined correctly, for most uses of a member, it will not fail, and there will be no performance hit because an exception will not be thrown.
When defining types and their members, you should define the members so that it is unlikely that they will fail for the common scenarios in which you expect your types to be used. If you later hear from users that they are dissatisfied with the performance due to exceptions being thrown, then and only then should you consider adding TryXxx methods. In other words, you should produce the best object model first and then, if users push back, add some TryXxx methods to your type so that the users who experience performance trouble can benefit. Users who are not experiencing performance trouble should continue to use the non-TryXxx versions of the methods because this is the better object model.
💡小结:异常处理和较常规的异常报告方式 ( HRESULT 和 特殊返回码等) 相比,很难看出两者在性能上的差异。如果写代码检查每个方法调用的返回值并将返回值 “漏” 给调用者,应用程序性能将受到严重影响。就算不考虑性能,由于要写代码检查每个方法的返回值,也必须进行大量额外的编程,而且出错几率也会大增。异常处理的优选方案。但异常处理也是有代价的:非托管 C++ 编译器必须生成代码来跟踪哪些对象被成功构造。编译器还必须生成代码,以便在一个异常被捕捉到的时候,调用每个已成功构造的对象的析构器。由编译器担负这个责任是很好的,但会在应用程序中生成大量薄记 (bookkeeping) 代码,对代码的大小和执行时间造成负面影响。另一方面,托管编译器就要轻松得多,因为托管对象在托管堆中分配,而托乱堆受垃圾回收器的监视。如对象成功构造,而且抛出了异常,垃圾回收器最终会释放对象的内存。编译器无需生成任何薄记代码来跟踪成功构造的对象,也无需保证析构器的调用。总之,不好判断异常处理到底会使应用程序增大多少额外的开销。在托管世界里更不好说,因为程序集的代码子在支持 .NET Framework 的任何平台上都能运行。所以,当程序集在 x86 处理器上运行时,JIT 编译器生成的用于管理异常处理的代码也会显著有别于程序集在 x64 或 ARM 处理器上运行时生成的代码。另外,与其他 CLR 实现 (比如 Microsoft 的 .NET Compact Framework 或者开源 Mono 项目) 关联的 JIT 编译器也有可能生成不同的代码。定义类型的成员时,应确保在一般使用情形中不会失败。只有用户以后因为抛出异常面对性能不满意时,才应考虑添加一些 TryXXX 方法。换言之,首先应建立一个最佳的对象模型。然后,只有在用户抱怨的时候,才在类型中添加一些 TryXXX 方法,帮助遭遇性能问题的用户改善性能。如果用户没有遇到性能问题,那么应继续使用方法的非 TryXXX 版本,因为那是更佳的对象模型。
# Constrained Execution Regions (CERs)
Many applications don’t need to be robust and recover from any and all kinds of failures. This is true of many client applications like Notepad.exe and Calc.exe. And, of course, many of us have seen Microsoft Office applications like WinWord.exe, Excel.exe, and Outlook.exe terminate due to unhandled exceptions. Also, many server-side applications, like web servers, are stateless and are automatically restarted if they fail due to an unhandled exception. Of course some servers, like SQL Server, are all about state management and having data lost due to an unhandled exception is potentially much more disastrous.
In the CLR, we have AppDomains (discussed in Chapter 22), which contain state. When an AppDomain is unloaded, all its state is unloaded. And so, if a thread in an AppDomain experiences an unhandled exception, it is OK to unload the AppDomain (which destroys all its state) without terminating the whole process.
By definition, a CER is a block of code that must be resilient to failure. Because AppDomains can be unloaded, destroying their state, CERs are typically used to manipulate any state that is shared by multiple AppDomains or processes. CERs are useful when trying to maintain state in the face of exceptions that get thrown unexpectedly. Sometimes we refer to these kinds of exceptions as asynchronous exceptions. For example, when calling a method, the CLR has to load an assembly, create a type object in the AppDomain’s loader heap, call the type’s static constructor, JIT IL into native code, and so on. Any of these operations could fail, and the CLR reports the failure by throwing an exception.
If any of these operations fail within a catch or finally block, then your error recovery or cleanup code won’t execute in its entirety. Here is an example of code that exhibits the potential problem.
private static void Demo1() { | |
try { | |
Console.WriteLine("In try"); | |
} | |
finally { | |
// Type1’s static constructor is implicitly called in here | |
Type1.M(); | |
} | |
} | |
private sealed class Type1 { | |
static Type1() { | |
// if this throws an exception, M won’t get called | |
Console.WriteLine("Type1's static ctor called"); | |
} | |
public static void M() { } | |
} |
When I run the preceding code, I get the following output.
In try
Type1's static ctor called
What we want is to not even start executing the code in the preceding try block unless we know that the code in the associated catch and finally blocks is guaranteed (or as close as we can get to guaranteed) to execute. We can accomplish this by modifying the code as follows.
private static void Demo2() { | |
// Force the code in the finally to be eagerly prepared | |
RuntimeHelpers.PrepareConstrainedRegions(); // System.Runtime.CompilerServices namespace | |
try { | |
Console.WriteLine("In try"); | |
} | |
finally { | |
// Type2’s static constructor is implicitly called in here | |
Type2.M(); | |
} | |
} | |
public class Type2 { | |
static Type2() { | |
Console.WriteLine("Type2's static ctor called"); | |
} | |
// Use this attribute defined in the System.Runtime.ConstrainedExecution namespace | |
[ReliabilityContract(Consistency.WillNotCorruptState, Cer.Success)] | |
public static void M() { } | |
} |
Now, when I run this version of the code, I get the following output.
Type2's static ctor called
In try
The PrepareConstrainedRegions method is a very special method. When the JIT compiler sees this method being called immediately before a try block, it will eagerly compile the code in the try’s catch and finally blocks. The JIT compiler will load any assemblies, create any type objects, invoke any static constructors, and JIT any methods. If any of these operations result in an exception, then the exception occurs before the thread enters the try block.
When the JIT compiler eagerly prepares methods, it also walks the entire call graph eagerly preparing called methods. However, the JIT compiler only prepares methods that have the ReliabilityContractAttribute applied to them with either Consistency.WillNotCorruptState or Consistency.MayCorruptInstance because the CLR can’t make any guarantees about methods that might corrupt AppDomain or process state. Inside a catch or finally block that you are protecting with a call to PrepareConstrainedRegions, you want to make sure that you only call methods with the ReliabillityContractAttribute set as I’ve just described.
The ReliabilityContractAttribute looks like this.
public sealed class ReliabilityContractAttribute : Attribute { | |
public ReliabilityContractAttribute(Consistency consistencyGuarantee, Cer cer); | |
public Cer Cer { get; } | |
public Consistency ConsistencyGuarantee { get; } | |
} |
This attribute lets a developer document the reliability contract of a particular method to the method’s potential callers. Both the Cer and Consistency types are enumerated types defined as follows.
enum Consistency { | |
MayCorruptProcess, MayCorruptAppDomain, MayCorruptInstance, WillNotCorruptState | |
} | |
enum Cer { None, MayFail, Success } |
If the method you are writing promises not to corrupt any state, use Consistency.WillNotCorruptState. Otherwise, document what your method does by using one of the other three possible values that match whatever state your method might corrupt. If the method that you are writing promises not to fail, use Cer.Success. Otherwise, use Cer.MayFail. Any method that does not have the ReliabiiltyContractAttribute applied to it is equivalent to being marked like this.
[ReliabilityContract(Consistency.MayCorruptProcess, Cer.None)] |
The Cer.None value indicates that the method makes no CER guarantees. In other words, it wasn’t written with CERs in mind; therefore, it may fail and it may or may not report that it failed. Remember that most of these settings are giving a method a way to document what it offers to potential callers so that they know what to expect. The CLR and JIT compiler do not use this information.
When you want to write a reliable method, make it small and constrain what it does. Make sure that it doesn’t allocate any objects (no boxing, for example), don’t call any virtual methods or interface methods, use any delegates, or use reflection because the JIT compiler can’t tell what method will actually be called. However, you can manually prepare these methods by calling one of these methods defined by the RuntimeHelpers’s class.
public static void PrepareMethod(RuntimeMethodHandle method) | |
public static void PrepareMethod(RuntimeMethodHandle method, | |
RuntimeTypeHandle[] instantiation) | |
public static void PrepareDelegate(Delegate d); | |
public static void PrepareContractedDelegate(Delegate d); |
Note that the compiler and the CLR do nothing to verify that you’ve written your method to actually live up to the guarantees you document via the ReliabiltyContractAttribute. If you do something wrong, then state corruption is possible.
💡注意:即使所有方法都提前准备好,方法调用仍有可能造成 StackOverflowException 。在 CLR 没有寄宿的前提下, StackOverflowException 会造成 CLR 在内部调用 Environment.FailFast 来立即终止进程。在已经寄宿的前提下, PrepareConstrainedRegions 方法检查是否剩下约 48 KB 的栈空间。栈空间不足,就在进入 try 块前抛出 StackOverflowException 。
You should also look at RuntimeHelper’s ExecuteCodeWithGuaranteedCleanup method, which is another way to execute code with guaranteed cleanup.
public static void ExecuteCodeWithGuaranteedCleanup(TryCode code, CleanupCode backoutCode, Object userData); |
When calling this method, you pass the body of the try and finally block as callback methods whose prototypes match these two delegates respectively.
public delegate void TryCode(Object userData); | |
public delegate void CleanupCode(Object userData, Boolean exceptionThrown); |
And finally, another way to get guaranteed code execution is to use the CriticalFinalizerObject class, which is explained in great detail in Chapter 21.
💡小结:许多服务器端应用程序 (比如 Web 服务器) 都是无状态的,会在因为未处理的异常而失败时自动重启。当然,某些服务器 (比如 SQL Server) 本来就是为状态管理而设计的。这种程序假如因为未处理的异常而发生数据丢失,后果将是灾难性的。在 CLR 中,我们有包含了状态的 AppDomain。AppDomain 卸载时,它的所有状态都会卸载。所以,如果 AppDomain 中的一个线程遭遇未处理的异常,可以在不终止整个进程的情况下卸载 AppDomain。根据定义,CER 是必须对错误有适应力的代码块。由于 AppDomain 可能被卸载,造成它的状态被销毁,所以一般用 CER 处理由多个 AppDomain 或进程共享的状态。如果要在抛出了非预期的异常时维护状态,CER 就非常有用。有时候这些异常称异步异常。 PrepareConstrainedRegions 是一个很特别的方法。JIT 编译器如果发现在一个 try 块之前调用了这个方法,就会提前编译与 try 关联的 catch 和 finally 块中的代码。JIT 编译器会加载任何程序集,创建任何类型对象,调用任何静态构造器,并对任何方法进行 JIT 编译。如果其中任何操作做成异常,这个异常会在线程进入 try 块之前发生。JIT 编译器提前准备方法时,还会遍历整个调用图,提前准备被调用的方法,前提是这些方法应用了 ReliabilityContractAttribute ,而且向这个特性实例的构造器传递的是 Consistency.WillNotCorruptState 或者 Consistency.MayCorruptInstance 枚举成员。这是由于假如方法会损坏 AppDomain 或进程的状态,CLR 便无法对状态一致性做出任何保证。在通过一个 PrepareConstrainedRegions 调用来保护的一个 catch 或 finally 块中,请确保只调用根据刚才的描述设置了 ReliabilityContractAttribute 的方法。 ReliabilityContractAttribute 特性允许开发者向方法的潜在调用者申明方法的可靠性协定 (reliability contract)。 Cer 和 Consistency 都是枚举类型。 Cer.None 这个值表明方法不进行 CER 保证。换言之,方法没有 CER 的概念。因此,这个方法可能失败,而且可能会、也可能不会报告失败。记住,大多数这些设置都为方法提供了一种方式来申明它向潜在的调用者提供的东西,使调用者知道什么可以期待。CLR 和 JIT 编译器不使用这种信息。如果想写一个可靠的方法,务必保持它的短小精悍,同时约束它做的事情。要保证它不分配任何对象 (例如不装箱)。另外,不调用任何虚方法或接口方法,不使用任何委托,也不使用反射,因为 JIT 编译器不知道实际会调用哪个方法。然而,可以调用 RuntimeHelper 类定义方法之一,从而手动准备这些方法。注意,编译器和 CLR 并不验证你写的方法真的符合通过 ReliabilityContractAttribute 来作出的保证。所以,如果犯了错误,状态仍有可能损坏。还应该关注一下 RuntimeHelper 的 ExecuteCodeWithGuaranteedCleanup 方法,它的资源保证得到清理的前提下才执行代码。最后,另一种保证代码得以执行的方式是使用 CriticalFinalizerObject 类。
# Code Contracts
Code contracts provide a way for you to declaratively document design decisions that you’ve made about your code within the code itself. The contracts take the form of the following:
Preconditions Typically used to validate arguments
Postconditions Used to validate state when a method terminates either due to a normal return or due to throwing an exception
Object Invariants Used to ensure an object’s fields remain in a good state through an object’s entire lifetime
Code contracts facilitate code usage, understanding, evolution, testing, documentation, and early error detection.10 You can think of preconditions, postconditions, and object invariants as parts of a method’s signature. As such, you can loosen a contract with a new version of your code, but you cannot make a contract stricter with a new version without breaking backward compatibility.
At the heart of the code contracts is the static System.Diagnostics.Contracts.Contract class.
public static class Contract { | |
// Precondition methods: [Conditional("CONTRACTS_FULL")] | |
public static void Requires(Boolean condition); | |
public static void EndContractBlock(); | |
// Preconditions: Always | |
public static void Requires<TException>(Boolean condition) where TException : Exception; | |
// Postcondition methods: [Conditional("CONTRACTS_FULL")] | |
public static void Ensures(Boolean condition); | |
public static void EnsuresOnThrow<TException>(Boolean condition) | |
where TException : Exception; | |
// Special Postcondition methods: Always | |
public static T Result<T>(); | |
public static T OldValue<T>(T value); | |
public static T ValueAtReturn<T>(out T value); | |
// Object Invariant methods: [Conditional("CONTRACTS_FULL")] | |
public static void Invariant(Boolean condition); | |
// Quantifier methods: Always | |
public static Boolean Exists<T>(IEnumerable<T> collection, Predicate<T> predicate); | |
public static Boolean Exists(Int32 fromInclusive, Int32 toExclusive, | |
Predicate<Int32> predicate); | |
public static Boolean ForAll<T>(IEnumerable<T> collection, Predicate<T> predicate); | |
public static Boolean ForAll(Int32 fromInclusive, Int32 toExclusive, | |
Predicate<Int32> predicate); | |
// Helper methods: [Conditional("CONTRACTS_FULL")] or [Conditional("DEBUG")] | |
public static void Assert(Boolean condition); | |
public static void Assume(Boolean condition); | |
// Infrastructure event: usually your code will not use this event | |
public static event EventHandler<ContractFailedEventArgs> ContractFailed; | |
} |
As previously indicated, many of these static methods have the [Conditional("CONTRACTS_ FULL")] attribute applied to them. Some of the helper methods also have the [Conditional ("DEBUG")] attribute applied to them. This means that the compiler will ignore any code you write that calls these methods unless the appropriate symbol is defined when compiling your code. Any methods marked with “Always” mean that the compiler always emits code to call the method. Also, the Requires, Requires, Ensures, EnsuresOnThrow, Invariant, Assert, and Assume methods have an additional overload (not shown) that takes a String message argument so you can explicitly specify a string message that should appear when the contract is violated.
By default, contracts merely serve as documentation because you would not define the CONTRACTS_FULL symbol when you build your project. In order to get some additional value out of using contracts, you must download additional tools and a Visual Studio property pane from http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx. The reason why all the code contract tools are not included with Visual Studio is because this technology is being improved rapidly. The Microsoft DevLabs website can offer new versions and improvements more quickly than Visual Studio itself. After downloading and installing the additional tools, you will see your projects have a new property pane available to them, as shown in Figure 20-9.
FIGURE 20-9 The Code Contracts pane for a Visual Studio project.
To turn on code contract features, select the Perform Runtime Contract Checking check box and select Full from the combo box next to it. This defines the CONTRACTS_FULL symbol when you build your project and invokes the appropriate tools (described shortly) after building your project. Now, at run time, when a contract is violated, Contract’s ContractFailed event is raised. Usually, developers do not register any methods with this event, but if you do, then any methods you register will receive a ContractFailedEventArgs object that looks like this.
public sealed class ContractFailedEventArgs : EventArgs { | |
public ContractFailedEventArgs(ContractFailureKind failureKind, | |
String message, String condition, Exception originalException); | |
public ContractFailureKind FailureKind { get; } | |
public String Message { get; } | |
public String Condition { get; } | |
public Exception OriginalException { get; } | |
public Boolean Handled { get; } // true if any handler called SetHandled | |
public void SetHandled(); // Call to ignore the violation; sets Handled to true | |
public Boolean Unwind { get; } // true if any handler called SetUnwind or threw | |
public void SetUnwind(); // Call to force ContractException; set Unwind to true | |
} |
Multiple event handler methods can be registered with this event. Each method can process the contract violation any way it chooses. For example, a handler can log the violation, ignore the violation (by calling SetHandled), or terminate the process. If any method calls SetHandled, then the violation will be considered handled and, after all the handler methods return, the application code is allowed to continue running unless any handler calls SetUnwind. If a handler calls SetUnwind, then, after all the handler methods have completed running, a System.Diagnostics.Contracts. ContractException is thrown. Note that this type is internal to MSCorLib.dll and therefore you cannot write a catch block to catch it explicitly. Also note that if any handler method throws an unhandled exception, then the remaining handler methods are invoked and then a ContractException is thrown.
If there are no event handlers or if none of them call SetHandled, SetUnwind, or throw an unhandled exception, then default processing of the contract violation happens next. If the CLR is being hosted, then the host is notified that a contract failed. If the CLR is running an application on a non-interactive window station (which would be the case for a Windows service application), then Environment.FailFast is called to instantly terminate the process. If you compile with the Assert On Contract Failure check box selected, then an assert dialog box will appear allowing you to connect a debugger to your application. If this option is not selected, then a ContractException is thrown.
Let’s look at a sample class that is using code contracts.
public sealed class Item { /* ... */ } | |
public sealed class ShoppingCart { | |
private List<Item> m_cart = new List<Item>(); | |
private Decimal m_totalCost = 0; | |
public ShoppingCart() { | |
} | |
public void AddItem(Item item) { | |
AddItemHelper(m_cart, item, ref m_totalCost); | |
} | |
private static void AddItemHelper(List<Item> m_cart, Item newItem, | |
ref Decimal totalCost) { | |
// Preconditions: | |
Contract.Requires(newItem != null); | |
Contract.Requires(Contract.ForAll(m_cart, s => s != newItem)); | |
// Postconditions: | |
Contract.Ensures(Contract.Exists(m_cart, s => s == newItem)); | |
Contract.Ensures(totalCost >= Contract.OldValue(totalCost)); | |
Contract.EnsuresOnThrow<IOException>(totalCost == Contract.OldValue(totalCost)); | |
// Do some stuff (which could throw an IOException)... | |
m_cart.Add(newItem); | |
totalCost += 1.00M; | |
} | |
// Object invariant | |
[ContractInvariantMethod] | |
private void ObjectInvariant() { | |
Contract.Invariant(m_totalCost >= 0); | |
} | |
} |
The AddItemHelper method defines a bunch of code contracts. The preconditions indicate that newItem must not be null and that the item being added to the cart is not already in the cart. The postconditions indicate that the new item must be in the cart and that the total cost must be at least as much as it was before the item was added to the cart. The postconditions also indicate that if AddItemHelper were to throw an IOException for some reason, then totalCost is unchanged from what it was when the method started to execute. The ObjectInvariant method is just a private method that, when called, makes sure that the object’s m_totalCost field never contains a negative value.
💡重要提示:前条件、后条件或不变性测试中引用的任何成员都一定不能有副作用 (改变对象的状态)。这是必须的,因为测试条件不应改变对象本身的状态。除此之外,前条件测试中引用的所有成员的可访问性都至少要和定义前条件的方法一样。这是必须的,因为方法的调用者应该能在调用方法之前验证它们符合所有前条件。另一方面,后条件或不变性测试中引用的成员可具有任何可访问性,只要代码能编译就行。可访问性之所以不重要,是因为后条件和不变性测试不影响调用者正确调用方法的能力。
💡重要提示:涉及继承时,派生类型不能重写并更改基类型中定义的虚成员的前条件。类似地,实现了接口成员的类型不能更改接口成员定义的前条件。如果一个成员没有定义显式的协定,那么成员将获得一个隐式协定,逻辑上这样表示:
Contract.Requires(true); |
由于协定不能在新版本中变得更严格 (否则会破坏兼容性),所以在引入新的虚 / 抽象 / 接口成员时,应仔细考虑好前条件。对于后条件和对象不变性,协定可以随意添加和删除,因为虚 / 抽象 / 接口成员中表示的条件和重写成员中表示的条件会 “逻辑 AND” 到一起。
So now you see how to declare contracts. Let’s now talk about how they function at run time. You get to declare all your precondition and postcondition contracts at the top of your methods where they are easy to find. Of course, the precondition contracts will validate their tests when the method is invoked. However, we don’t want the postcondition contracts to validate their tests until the method returns. In order to get the desired behavior, the assembly produced by the C# compiler must be processed by the Code Contract Rewriter tool (CCRewrite.exe, found in C:\Program Files (x86)\Microsoft\Contracts\Bin), which produces a modified version of the assembly. After you select the Perform Runtime Contract Checking check box for your project, Visual Studio will invoke this tool for you automatically whenever you build the project. This tool analyzes the IL in all your methods and it rewrites the IL so that any postcondition contracts are executed at the end of each method. If your method has multiple return points inside it, then the CCRewrite.exe tool modifies the method’s IL code so that all return points execute the postcondition code prior to the method returning.
The CCRewrite.exe tool looks in the type for any method marked with the [ContractInvariantMethod] attribute. The method can have any name but, by convention, people usually name the method ObjectInvariant and mark the method as private (as I’ve just done). The method must accept no arguments and have a void return type. When the CCRewrite.exe tool sees a method marked with this attribute, it inserts IL code at the end of every public instance method to call the ObjectInvariant method. This way, the object’s state is checked as each method returns to ensure that no method has violated the contract. Note that the CCRewrite.exe tool does not modify a Finalize method or an IDisposable’s Dispose method to call the ObjectInvariant method because it is OK for an object’s state to be altered if it is considered to be destroyed or disposed. Also note that a single type can define multiple methods with the [ContractInvariantMethod] attribute; this is useful when working with partial types. The CCRewrite.exe tool will modify the IL to call all of these methods (in an undefined order) at the end of each public method.
The Assert and Assume methods are unlike the other methods. First, you should not consider them to be part of the method’s signature, and you do not have to put them at the beginning of a method. At run time, these two methods perform identically: they just verify that the condition passed to them is true and throw an exception if it is not. However, there is another tool, the Code Contract Checker (CCCheck.exe), which analyzes the IL produced by the C# compiler in an attempt to statically verify that no code in the method violates a contract. This tool will attempt to prove that any condition passed to Assert is true, but it will just assume that any condition passed to Assume is true and the tool will add the expression to its body of facts known to be true. Usually, you will use Assert and then change an Assert to an Assume if the CCCheck.exe tool can’t statically prove that the expression is true.
Let’s walk through an example. Assume that I have the following type definition.
internal sealed class SomeType { | |
private static String s_name = "Jeffrey"; | |
public static void ShowFirstLetter() { | |
Console.WriteLine(s_name[0]); // warning: requires unproven: index < this.Length | |
} | |
} |
When I build this code with the Perform Static Contract Checking function turned on, the CCCheck.exe tool produces the warning shown as a comment in the preceding code. This warning is notifying me that querying the first letter of s_name may fail and throw an exception because it is unproven that s_name always refers to a string consisting of at least one character.
Therefore, what we’d like to do is add an assertion to the ShowFirstLetter method.
public static void ShowFirstLetter() { | |
Contract.Assert(s_name.Length >= 1); // warning: assert unproven | |
Console.WriteLine(s_name[0]); | |
} |
Unfortunately, when the CCCheck.exe tool analyzes this code, it is still unable to validate that s_name always refers to a string containing at least one letter, so the tool produces a similar warning. Sometimes the tool is unable to validate assertions due to limitations in the tool; future versions of the tool will be able to perform a more complete analysis.
To override shortcomings in the tool or to claim that something is true that the tool would never be able to prove, we can change Assert to Assume. If we know for a fact that no other code will modify s_name, then we can change ShowFirstLetter to this.
public static void ShowFirstLetter() { | |
Contract.Assume(s_name.Length >= 1); // No warning at all now! | |
Console.WriteLine(s_name[0]); | |
} |
With this version of the code, the CCCheck.exe tool just takes our word for it and concludes that s_name always refers to a string containing at least one letter. This version of the ShowFirstLetter method passes the code contract static checker without any warnings at all.
Now, let’s talk about the Code Contract Reference Assembly Generator tool (CCRefGen.exe). Running the CCRewrite.exe tool to enable contract checking helps you find bugs more quickly, but all the code emitted during contract checking makes your assembly bigger and hurts its run-time performance. To improve this situation, you use the CCRefGen.exe tool to create a separate contract reference assembly. Visual Studio invokes this tool for you automatically if you set the Contract Reference Assembly combo box to Build. Contract assemblies are usually named AssemName.Contracts.dll (for example, MSCorLib.Contracts.dll), and these assemblies contain only metadata and the IL that describes the contracts—nothing else. You can identify a contract reference assembly because it will have the System.Diagnostics.Contracts.ContractReferenceAssemblyAttribute applied to the assembly’s assembly definition metadata table. The CCRewrite.exe tool and the CCCheck.exe tool can use contract reference assemblies as input when these tools are performing their instrumentation and analysis.
The last tool, the Code Contract Document Generator tool (CCDocGen.exe), adds contract information to the XML documentation files already produced by the C# compiler when you use the compiler’s /doc:file switch. This XML file, enhanced by the CCDocGen.exe tool, can be processed by Microsoft’s Sandcastle tool to produce MSDN-style documentation that will now include contract information.
💡小结:代码协定 (code contract) 提供了直线在代码中声明代码设计决策的一种方式。代码协定有利于代码的使用、理解、进化、测试、文档和早期错误检测。可将前条件、后条件和对象不变性想象为方法签名的一部分。所以,代码新版本的协定可以变得更宽松。但不能变得更严格,否则会破坏向后兼容性。代码协定的核心是静态类 System.Diagnostics.Contracts.Contract 。其中许多静态方法都应用了 [Conditional("CONTRACTS_FULL")] 特性。有的辅助方法还应用了 [Conditional("DEBUG")] ,意味着除非定义了恰当的符号,否则编译器会忽略调用这些方法的任何代码。标记 “Always” 的任何方法意味着编译器总是生成调用方法的代码。另外, Requires , Requires<TException> , Ensures , EnsuresOnThrow , Invariant , Assert 和 Assume 方法有一个额外的重载版本 (这里没有列出),它获取一个 String 实参,用于显式指定违反协定时显示的字符串消息。协定默认只作为文档使用,因为生成项目时没有定义 CONTRACTS_FULL 符号。为了发掘协定的附加价值,必须下载额外的工具和一个 Visual Studio 属性窗格,网址是 http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx。